
The FineTuneBench Paradox
GPT-4o mini scored 98% on one knowledge injection benchmark. On another, the same model, the same API, the same commercial fine-tuning pipeline scored 6%. Average those two numbers, and you get 37%, and that 37% is what every LLM architecture newsletter ran in late 2024 as proof that fine-tuning was broken.
They were right. But for the wrong reason. And the practical decisions that followed (abandon fine-tuning, default to RAG for everything, treat the two as competing architectural philosophies) set a new generation of teams up for a different set of expensive mistakes.
The 98% result is not a fluke. GPT-4o mini achieved it on the Latest News knowledge (rephrased questions), where the injected knowledge was structured, factual, and linguistically close to the model’s pre-training distribution. The 6% result came from GPT-4o mini on Code knowledge updates: technically dense, highly structured, and as far from “news summary” as content can get. The same commercial fine-tuning API that appears to be a reliable knowledge injection mechanism on one task appears to be a random number generator on another.
This variance is the central finding of FineTuneBench (arXiv 2411.05059), a benchmark specifically designed to test whether commercial LLM fine-tuning APIs actually infuse knowledge into models or teach them to memorise the surface form of training examples. The methodology is elegant in its brutality: create evaluation sets from genuinely post-cutoff information, then test whether fine-tuned models can answer rephrased versions of training questions — versions they have never seen, yet for which the underlying knowledge should transfer if the model truly learned the fact. The average generalisation accuracy across all models and all knowledge types was 37% for new knowledge and 19% for knowledge updates. Gemini 1.5 Pro on new knowledge never exceeded 5%.
The teams that looked at these numbers and said, “Fine-tuning is broken, use RAG,” drew a reasonable but incomplete conclusion. They solved the wrong problem. Commercial APIs do not fail because the fine-tuning technique is fundamentally flawed. They fail because teams are using fine-tuning to do something it is not designed to do: store dynamic factual knowledge in model weights, where it competes with billions of pre-training parameters and degrades or fails to generalise from day one.
The more consequential insight buried in FineTuneBench’s variance is this: the 98% outlier proves that fine-tuning can generalise when the knowledge type aligns with what optimisation is actually good at. And the entire research corpus from 2023 to 2026 has been quietly converging on what fine-tuning is actually good at, which is not knowledge injection at all, but something more valuable and less understood: teaching a model how to behave rather than what to know, and teaching it how to read imperfect retrieval output rather than what facts to retrieve.
The correct architecture today is not RAG or fine-tuning. It is a three-layer stack where each technique handles a distinct problem for which it is structurally suited.
The False Dichotomy
Three independent research groups, working on different problems, with different datasets, in different domains, arrived at the same structural conclusion: RAG and fine-tuning are not competing choices. They are additive.
The agriculture study (arXiv 2401.08406) is the most direct evidence. Testing Llama2-13B, GPT-3.5, and GPT-4 on a domain-specific QA task, the researchers found that fine-tuning alone improved accuracy by approximately 6 percentage points over baseline. RAG alone improved it by approximately 5 points. But the combination improved it by roughly 11 points — not the 5-6 one would expect from a single technique, not the 11 one might guess by adding them, but the 11 that emerges when two complementary systems each handle what they handle well. Geographic knowledge similarity improved from 47% to 72% in the combined condition. Neither method was redundant; neither was sufficient.
RAFT (arXiv 2403.10131) makes the same point from a different angle. The research question RAFT asks is not “should I use RAG or fine-tuning” but “what would a model that has been specifically trained to consume RAG output look like?” The answer – a model trained on mixed golden and distractor document sets with chain-of-thought citation – improved on function-calling benchmarks by 31.41 percentage points compared to standard domain-specific fine-tuning plus RAG. RAFT is not a competitor to RAG. It is fine-tuning that makes RAG better.
DRAG (arXiv 2310.01558) arrives at the same mechanism from a third direction. The DRAG researchers observed that irrelevant retrieved context does not merely fail to help — it actively hurts performance. Llama-2-13B suffered roughly a 10-point performance drop on Natural Questions from random-quality retrieval. More counterintuitively, even top-1 Google Search retrieval hurt performance on StrategyQA and Fermi problems — reasoning tasks where the retrieved context introduced noise into reasoning chains that would have performed better without any retrieval at all. The solution DRAG demonstrates is a small fine-tuning dataset — 500 to 1,584 examples — that teaches the model retrieval awareness: when to use retrieved context, when to discount it, and when to set it aside entirely. The gain across three benchmarks was 2.4 to 2.7 percentage points.
The pattern across these three papers is consistent: fine-tuning and RAG compound are used when addressing different parts of the system. Fine-tuning changes the model’s behavioural patterns; how it reasons, responds to noise, and formats outputs. RAG changes the model’s access to information & what it can reference at inference time. These are different problems. Solving both solves more than solving either.
The binary framing persists not because it is empirically defensible but because it is commercially convenient. Every vendor offering primarily a fine-tuning API frames the decision as fine-tuning versus something else. Every vendor offering primarily a vector database frames RAG as the answer. The practitioners caught in the middle, without the time to read three papers in three different venues, default to the framing they encounter most often.
The field should be asking which problems each technique solves. It has been asking which to choose.
What Fine-Tuning Actually Does and Fails At
The FineTuneBench results would be damning if they were uniform. They are not. The 37% average conceals a distribution that carries the real information: 6% to 98% variance on the same technique, the same provider, from the same commercial API.
Understanding that variance requires understanding the mechanism. When a commercial fine-tuning API receives a training set, the optimisation process adjusts model weights to improve performance on training examples. If those training examples are structured consistently (e.g., news stories following a recognisable format, facts that fit naturally into the model’s existing knowledge representations), the model can generalise from the training distribution to rephrased versions of the same facts. This is what happened with GPT-4o mini on Latest News at 98%. The knowledge type was congruent with the pre-training distribution, the examples were structurally consistent, and the model could generalise the pattern.
Code knowledge is different. The rephrased variants of code-related facts require the model to update highly specific, structurally constrained knowledge representations— such as function signatures, API parameters, and version-specific behaviours. The model cannot generalise from “function X takes parameter Y” to “what does function X do?” the way it can generalise from “the election occurred on date Z” to “when did the election occur?” The optimisation process learns the surface form of the training examples. It does not restructure the underlying knowledge representation, because that is not what gradient descent does. GPT-4o on Code generalisation: 6%.
This distinction is the entire decision. Commercial fine-tuning APIs are not knowledge injection mechanisms. They are behavioural pattern-modification mechanisms that also update knowledge representations when the knowledge type is structurally compatible with pattern learning. The 19% success rate on knowledge updates, worse than the 37% on new knowledge, is especially revealing: when the model has an existing fact in its weights and the fine-tuning target conflicts with that fact, the update creates interference. The old representation resists the new one, gradient descent tries to reconcile them, and the result satisfies neither.
The LoRA research (arXiv 2410.21228) reveals a parallel failure mode in self-hosted fine-tuning that is more subtle and more dangerous because it is invisible on the benchmarks teams use to validate their training runs.
LoRA fine-tuning works by constraining weight updates to a low-dimensional subspace. This constraint makes it parameter-efficient: rather than updating all model weights, it updates two small matrices whose product approximates the full weight update. The problem is that this constraint forces the optimiser to introduce what the paper calls “intruder dimensions” – high-magnitude singular vectors that are orthogonal to the pre-trained weight space. These new directions dominate the adapted model’s behaviour and, in doing so, actively suppress access to pre-training knowledge stored in the existing weight-space directions.
The Spearman correlation between intruder dimension count and catastrophic forgetting on pre-training tasks is ρ=0.971 (p<0.001) in the RoBERTa experiments, and ρ=0.59 (p=0.0006) on LLaMA2-7B. The effect is not subtle. Scaling down intruder dimensions by a factor of λ=0.7 post-training reduces forgetting by 33-34%, with only a 0.1% drop in accuracy on the fine-tuned task itself. The PEFT library now ships this mitigation as reduce_intruder_dimension().
The production implication is severe for teams running LoRA on monthly retraining cycles: intruder dimension accumulation is not a one-time effect. Each training iteration introduces new intruder dimensions. Without mitigation, a model fine-tuned six times on monthly knowledge updates has accumulated six rounds of pre-training capability erosion – none of which is visible on the task-specific benchmark used to validate each run.
What fine-tuning reliably does well is what the benchmark paradigm makes hardest to test: behavioural consistency. If you need a model that always returns valid JSON, LoRA trained on 1,000 JSON-formatted examples is highly effective. If you need a model to respond in a specific domain voice, follow a particular reasoning pattern, or call functions with specific parameter conventions, fine-tuning encodes these patterns in the weights in a way that prompting cannot guarantee at production scale and with acceptable latency. The decision framework condition is clear: behavioural change, not knowledge change, is where fine-tuning delivers reliable ROI.
The teams that succeeded with commercial fine-tuning APIs, the 98% results, were not doing knowledge injection. They were doing pattern reinforcement on knowledge the model already approximately knew, structured in a way the model could generalise. The teams that failed were attempting to solve a retrieval problem with a training mechanism.
The Hidden TCO: Data Is the Budget, Compute Is the Distraction
Most fine-tuning cost estimates begin with the training run. A QLoRA run on a 7B model takes three to five hours on an A100-class GPU at cloud rates of roughly $1-2 per hour. Total compute cost: $3-$10. Full fine-tuning on a 70B model: $2,000-$10,000 per run. Commercial API fine-tuning for GPT-4o mini: $25-$200. These numbers are accurate, visible, and completely misleading as a basis for architectural decisions.
The actual cost distribution for a first-time fine-tuning investment is approximately as follows: data preparation accounts for 70-80% of the total cost; computing accounts for 10-20%. The training run that teams agonise over is the cheap part. The expensive part is the labelled dataset that makes the training run meaningful and that dataset requires domain experts, not ML engineers, to build. For teams that budget only the training run, this distribution creates a 10 to 50 times gap between initial estimate and actual spend.
It is worth being precise about where the 10-50x multiplier applies. This is the gap between a team’s initial compute-only estimate and the actual spend for a first-time fine-tuning investment without existing MLOps infrastructure. A mature team with an established labelled dataset, functioning evaluation harness, and deployed serving infrastructure will see a 3-5x multiplier, not 10-50x. One valid objection to this figure is that organisations already operating a fine-tuning capability can amortise the infrastructure investment across multiple models, which is accurate. The warning is targeted at teams evaluating their first fine-tuning investment and it is directionally correct even when the upper bound is aggressive.
The honest framing for RAG TCO is that it is not cheap either, just differently structured. Chunking strategy tuning alone takes 40 or more hours to optimise correctly. The Seven Failure Points paper (arXiv 2401.05856) identifies seven systematic RAG failure modes that cannot be designed out at build time and require ongoing monitoring costing 2 to 8 hours per month. Re-embedding when models change, or documents are reformatted, is a recurring cost. The accurate comparison is that RAG failure modes are infrastructure failures that can be recovered through pipeline tuning without expensive data re-collection. Fine-tuning failure modes are data failures that can be recovered only through expert relabelling. And RAG infrastructure is reusable across knowledge bases and use cases in ways that task-specific fine-tuning investments are not.
The three-line mental model for TCO conversations: compute is visible and cheap; data curation is invisible and dominant; retraining cycles are invisible, recurring, and unbudgeted. Teams that build a fine-tuning cost model and stop at the first line will be surprised by the second, ambushed by the third, and three months in, will be asking why the model no longer knows about the Q3 product update.
The Three-Layer AI Adaptation Stack
The binary framing of RAG versus fine-tuning obscures the architecture that the research consistently supports: three distinct layers, each handling a different problem, each with its own cost structure and decision trigger.
Layer 1: Retrieval. What the model knows. This layer is responsible for giving the model access to information that changes over time: current documentation, proprietary knowledge bases, recent events, and domain-specific facts. RAG is the correct mechanism at this layer because it externalises the knowledge storage problem to a document corpus that can be updated without retraining. The decision to invest in this layer is simple. If the model needs to answer questions about information that postdates its training cutoff, or information specific to your organisation, this layer is mandatory. The investment signal is FineTuneBench’s 19-37% success rate: when knowledge changes, attempting to store it in weights is reliably unreliable.
Layer 1 investment runs through LangChain or LlamaIndex pipelines, vector stores (Chroma locally, Pinecone or Qdrant for managed), and RAGAS evaluation to monitor quality against the Seven Failure Points taxonomy. The ceiling for this layer is determined by retrieval quality, how well the right documents surface, and by the generator’s ability to use them, which is the Layer 3 problem.
Layer 2: Behavioural fine-tuning. How the model acts. This layer is responsible for encoding stable behavioural patterns that prompting cannot reliably guarantee: output format consistency, domain vocabulary, reasoning style, and latency-critical classification decisions. Fine-tuning is the correct mechanism at this layer because behavioural patterns are structurally compatible with what gradient descent actually does — it modifies the probability distribution over outputs in ways that generalise. The 98% FineTuneBench result on Latest News generalisation is a behavioural pattern result: the model learned a structure for processing news-like facts, not the facts themselves.
The decision signal for Layer 2 investment is: after building Layer 1, is the quality gap due to how the model responds (wrong format, inconsistent tone, incorrect reasoning style) or to what the model knows (wrong facts, outdated information, missing domain knowledge)? If the gap is behavioural, Layer 2 is the correct investment. If the gap is knowledge-based, it is a Layer 1 problem that Layer 2 will not solve – FineTuneBench has demonstrated this quantitatively.
Layer 2 investment requires the most rigorous data pipeline of the three layers. The validation approach must go beyond task-specific benchmark accuracy to include: rephrased-question generalisation testing (to detect the surface-pattern memorisation failure FineTuneBench reveals), pre-training capability retention testing on held-out tasks (to detect the intruder dimension forgetting LoRA Illusion reveals), and intruder dimension auditing via reduce_intruder_dimension() as post-training hygiene for any LoRA fine-tuning run.
Layer 3: Robustness training. How the model reads. This is the underinvested layer – the one the RAG versus fine-tuning debate has almost entirely obscured. It is responsible for a problem that neither pure retrieval nor pure behavioural fine-tuning addresses: production RAG systems deliver imperfect context, and a model that has not been trained to handle imperfect context will degrade in ways that neither better retrieval nor better prompting can fully repair.
The DRAG and RAFT research converges on the same mechanism for this layer. Train the model on examples that include both relevant and irrelevant retrieved documents. Teach it to identify which context to use, which to discount, and when the retrieved context is actively misleading. The training dataset is small, 500 to 1,584 examples are sufficient for meaningful gains, and the training time is measured in hours, not days.
To make this architecture concrete, consider a legal document assistant. Layer 1 retrieves relevant case law and contract clauses from a vector store containing 100,000 documents. This layer handles knowledge: the model can reference current precedents, specific contract language, and recent regulatory updates. Layer 2 encodes the behavioural patterns of legal reasoning — structured analysis format, citation conventions, and the specific reasoning style expected by the legal team. This layer handles behaviour: the model responds like a trained legal professional, not a generic assistant. Layer 3 trains the model to handle the retrieval imperfections that will inevitably occur at Layer 1: cases where an adjacent but wrong precedent surfaces in the top-K results, or where a relevant clause is buried in a long contract and partially captured by a chunk boundary. This layer handles robustness: the model doesn’t fail when retrieval isn’t perfect, which is most of the time.
Each layer has a distinct failure signal:
- Layer 1 fails when RAGAS Context Precision or Context Recall drops – the retriever is not surfacing the right documents.
- Layer 2 fails when the model’s output format, tone, or reasoning structure deviates despite correct retrieval.
- Layer 3 fails when RAGAS Noise Sensitivity rises above acceptable thresholds — the model’s performance degrades when irrelevant context is present in the retrieved set.
Most teams today are investing heavily in Layer 1, building Layer 2 when they should be building Layer 3 first, and are not aware that Layer 3 is a distinct investment category. The research literature has already demonstrated that Layer 3, at the right moment, delivers higher ROI per dollar than continued Layer 1 investment.
The Underinvested Layer: Retrieval Robustness Training
The DRAG paper’s most counterintuitive finding deserves to be stated plainly: in their StrategyQA and Fermi experiments, even top-1 Google Search retrieval — the best retrieval quality available — actively degraded model performance compared to answering the same questions without any retrieval at all.
This is not an edge case. It is the production condition for any reasoning-intensive RAG application. When retrieved context contains information that is adjacent to but not exactly relevant to the question – a common occurrence in real queries against real document corpora – the model’s reasoning is pulled off course by the irrelevant signal. The generator does not have a reliable mechanism for distinguishing “this retrieved document is exactly what I need” from “this retrieved document looks relevant but will corrupt my answer if I weight it too heavily.” Without training, it treats both cases the same way.
DRAG’s solution is a fine-tuning dataset of 500 to 1,584 examples constructed by mixing relevant and irrelevant contexts with QA pairs. The model trained on this dataset learns retrieval awareness: the ability to condition its response on retrieval quality rather than treating all retrieved context as equally authoritative. The gain across three benchmarks (Natural Questions, 2WikiMultiHopQA, StrategyQA) was 2.4 to 2.7 percentage points — modest in absolute terms but substantial relative to the small training dataset and minimal training time.
RAFT (arXiv 2403.10131) achieves larger gains through a more structured training approach. Each training example consists of one golden document (the relevant source) plus four distractor documents, and the model is trained to generate chain-of-thought reasoning with verbatim citations from the relevant source. The reasoning chain forces the model to explicitly identify which document it is drawing on and why — teaching a meta-cognitive skill that transfers to production retrieval conditions. On the Gorilla HuggingFace function-calling benchmark, RAFT achieved 74.00% versus 42.59% for domain-specific fine-tuning plus RAG, a gain of 31.41 percentage points.
One caveat to the +31.41% figure is worth acknowledging: the HuggingFace baseline was 42.59% for the DSF+RAG condition, while the standard RAG baseline on HotpotQA was essentially 0.03% — a floor effect that makes the percentage gain appear larger than it would from a more competitive baseline. The PubMed result, where RAFT achieved 73.30% versus 58.8% for the baseline RAG approach, is a more honest representation of production-realistic gains: +14.5 percentage points from a baseline that was already functioning. For production systems, the conservative expectation is 2.4 to 14.5 percentage points of improvement from retrieval-robustness training, concentrated in domains with mixed-relevance retrieval.
The ROI calculation is asymmetric in favour of this investment. Retrieval robustness training costs approximately $10 to $50 in compute for a 7B model (a few hours with QLoRA) and $1,000 to $5,000 for dataset construction — the dominant cost being the labelling of 500 to 1,500 mixed-quality retrieval examples. Compare this against the alternative: upgrading the retriever. Moving from a basic embedding-based retriever to a hybrid BM25 plus dense vector search ensemble with a reranker is a 4 to 8 week engineering project that requires integration across the retrieval stack, evaluation infrastructure to measure the improvement, and ongoing maintenance as the document corpus evolves. The probability that the retriever upgrade delivers greater quality improvement than the generator robustness training is low once the retriever has reached a reasonable baseline quality (RAGAS Context Precision above 0.75-0.80).
The practical trigger for Layer 3 investment is the RAGAS Noise Sensitivity metric. RAGAS (explodinggradients/ragas) computes Noise Sensitivity as the impact of irrelevant context on answer quality: introduce known-irrelevant documents into the retrieval results and measure the accuracy degradation. A Noise Sensitivity score above 0.5 indicates the generator is being meaningfully hurt by retrieval noise. This is the signal to invest in robustness training rather than further retriever tuning. The evaluation costs approximately $0.50 to $2.00 per 100 samples at GPT-4o mini pricing, making it an accessible diagnostic before committing to training infrastructure.
The tool gap here is real and represents one of the clearest opportunities in the LLM tooling space. There is no automated pipeline for generating RAFT-style training data from an existing RAG system. Teams must manually construct the 1-golden plus 4-distractor training sets. An automated generator — one that takes a vector store and production query logs, samples high-scoring documents as golden examples, retrieves plausible distractors, and uses a strong LLM to generate chain-of-thought annotations — does not yet exist as a packaged tool. Until it does, RAFT adoption is constrained by friction in dataset construction.
The Failure Visibility Matrix
Every architectural decision has invisible failure modes. The dangerous ones are not the failures that produce obvious errors — they are the failures that pass your pre-deployment validation and manifest in production on inputs you did not test. The following matrix maps each major technique to its characteristic invisible failure and the measurement that would have caught it.
| Technique | Characteristic Invisible Failure | How It Appears in Production | Correct Detection Measurement |
| LoRA / QLoRA fine-tuning | Intruder dimension forgetting: pre-training capabilities erode silently across iterative fine-tuning runs | Model responds correctly to domain tasks but fails on general reasoning, multi-step problems, or cross-domain questions unrelated to training | Pre-training capability retention testing on held-out tasks before and after fine-tuning;
reduce_intruder_dimension() audit via SVD analysis; ρ=0.971 correlation with pre-training loss (arXiv 2410.21228) |
| Commercial API fine-tuning | Surface pattern memorisation: model achieves 37% average generalisation on rephrased questions despite 100% accuracy on training examples | Model answers training questions correctly but fails to paraphrase variants, user queries with different phrasing, or questions that combine fine-tuned knowledge with general knowledge | Rephrased-question generalisation test (FineTuneBench methodology): generate 5 paraphrase variants of 50 training questions, measure accuracy on variants not seen during training; anything below 70% is a red flag (arXiv 2411.05059) |
| Standard RAG (retrieve + prompt, no robustness training) | Noise-induced degradation: model performance drops when retrieved context contains adjacent-but-irrelevant documents — the normal production condition | Model answers simple questions well but degrades on complex or multi-step queries, where the retrieved context is of mixed quality | RAGAS Noise Sensitivity metric: inject known-irrelevant documents into retrieval results for 100 test queries, measure accuracy degradation; >0.5 score indicates robustness training investment is warranted (arXiv 2310.01558) |
| Hybrid retrieval (BM25 + dense ensemble) | Recall-at-the-cost-of-precision: more documents surface, but more noise enters the context window, triggering the DRAG failure mode on reasoning tasks | Retrieval recall improves, but answer accuracy on multi-hop or reasoning questions degrades relative to simpler retrieval | Component-level RAGAS evaluation separating Context Precision from Context Recall; rising Noise Sensitivity score despite rising Context Recall indicates the hybrid configuration is trading the wrong tradeoff for reasoning tasks |
| Behavioural fine-tuning without LoRA mitigation | Format consistency at the cost of knowledge breadth: the model reliably produces the correct output format but generalises less well to edge cases and off-distribution queries | Model handles standard queries with impressive format consistency but fails on unusual user phrasings, multi-domain questions, or queries near the boundary of the training distribution | Adversarial evaluation with out-of-distribution queries specifically designed to probe the edges of the fine-tuning target; intruder dimension audit as standard post-training hygiene |
| RAFT without automated training data generation | Training distribution narrowness: model becomes robustly good at handling retrieval noise in the specific domains represented in the RAFT training set, but fails to generalise robustness to new domain expansions | Robustness training improves quality on benchmark domains but shows no improvement (or even degradation) when the knowledge base is expanded to new document types. | Separate evaluation sets for in-distribution and out-of-distribution retrieval conditions; measure Noise Sensitivity independently for each document domain in the knowledge base |
This matrix is a pre-deployment checklist, not a post-incident diagnostic. The time to run these measurements is before committing to an architectural choice, not after six months of production traffic reveals the failure mode.
Code Examples
The following examples connect the research to concrete implementation paths. All code is drawn from the actual repositories analysed for this article.
Standard RAG pipeline with LangChain:
https://gist.github.com/vicpada/c6e9226d010cfc45cbdfc395c3e06f7b
Note: the chunk_size=1000, chunk_overlap=200 defaults are from documentation examples. The Seven Failure Points research documents that chunking strategy tuning requires 40 or more hours for production optimisation — treat these as starting values, not production settings.
RAGAS evaluation with Noise Sensitivity:
https://gist.github.com/vicpada/64227b8b991d598132058685689b4daf
Costs approximately $0.50 to $2.00 per 100 samples at GPT-4o mini pricing — a mandatory pre-deployment measurement, not an optional optimisation.
LLaMA-Factory SFT for RAFT-style robustness training:
https://gist.github.com/vicpada/7ecf1c29111d951319b84b53466d2d7f
The training data construction is the hard part: for each training example, retrieve the golden document (highest relevance score from your vector store for a given question) plus four distractor documents (lower relevance but topically adjacent), then use GPT-4o to generate a chain-of-thought answer that cites the golden document verbatim—budget 10 to 20 hours for dataset construction for 500 examples.
PEFT reduce_intruder_dimension post-training mitigation:
https://gist.github.com/vicpada/2d3150fc51c17f50b035dfa5c2dd6bed
This call is two lines of code. It is available in the production PEFT library. The research established a ρ = 0.971 correlation between intruder dimensions and catastrophic forgetting. That most QLoRA deployments do not include it is a gap between what the research shows and what practitioners routinely do.
The Decision Framework
The decision is sequential, not binary. Work through these questions in order, and stop when you have your answer.
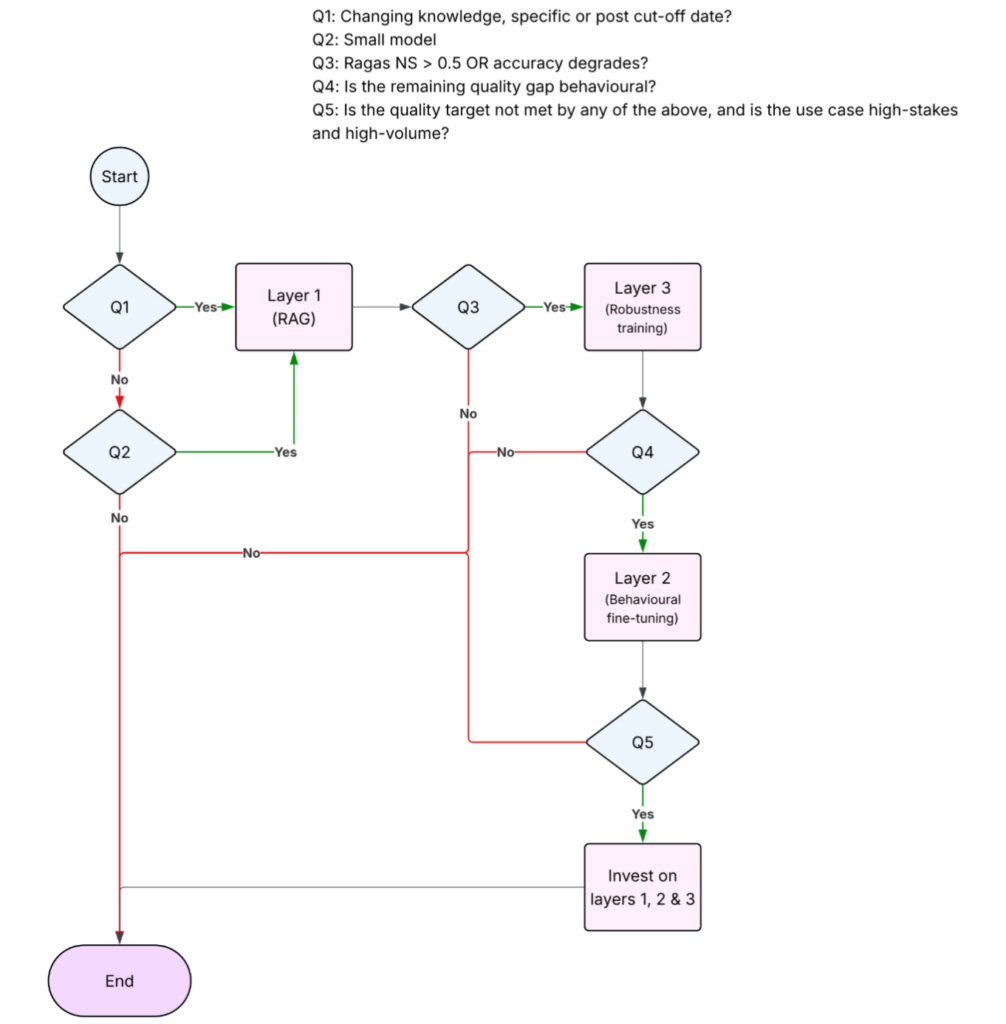
Does the model need access to knowledge that changes faster than monthly, that is specific to your organisation, or that postdates the model’s training cutoff? If yes, RAG is the correct architecture for that knowledge. FineTuneBench’s 19% success rate on knowledge updates makes fine-tuning for this purpose a gamble with poor odds. Build Layer 1 first. This applies regardless of model size, query volume, or latency requirements.
Are you using smaller open-source models (3B-12B parameters) as your primary deployment targets? If yes, the case for RAG is particularly strong. LaRA (arXiv 2502.09977) shows 6 to 38% accuracy improvements from RAG over long-context approaches for models in this range, even at 128k context windows. The +3.68% overall RAG advantage persists even at 128k context across all model sizes. The long-context threat to RAG — the argument that expanding context windows will make retrieval infrastructure obsolete — is real at the frontier tier. For GPT-4o on reasoning-heavy comparison tasks, LaRA shows RAG trailing long-context by 15.22 percentage points at 32k context. That finding is accurate, and engineering teams choosing frontier proprietary models for reasoning-intensive tasks should benchmark both architectures. For the majority of production deployments that use smaller models for cost reasons, the long-context threat is not the primary concern.
After building and evaluating your RAG system, does your RAGAS Noise Sensitivity score exceed 0.5, or does accuracy degrade meaningfully when your retriever returns mixed-quality results? If yes, invest in Layer 3 before Layer 2. RAFT/DRAG robustness training on 500 to 1,500 examples will deliver 2.4 to 14.5 percentage points of improvement for a training compute cost of $10 to $50 and a dataset construction cost of $1,000 to $5,000. This investment comes before behavioural fine-tuning in the priority order because it addresses the generator bottleneck that limits all subsequent quality improvements. A behaviorally fine-tuned model that cannot handle retrieval noise will underperform a behaviorally untuned model that can.
After addressing retrieval quality and retrieval robustness, is the remaining quality gap behavioural — e.g., wrong output format, inconsistent reasoning style, domain vocabulary mismatches, or latency requirements that RAG’s 50-500ms retrieval overhead cannot satisfy? If yes, behavioural fine-tuning (Layer 2) is the correct investment. Use LLaMA-Factory for self-hosted fine-tuning; validate with rephrased-question generalisation testing before deployment; apply reduce_intruder_dimension() as post-training hygiene for every LoRA run; budget data preparation at 70 to 80% of total cost and compute at 10 to 20%.
Is the quality target not met by any of the above, and is the use case high-stakes and high-volume (above 1 million queries per month)? This is the hybrid architecture case that the agriculture study’s combined result of +11 percentage points validates. The combination of a fine-tuned behavioural layer on top of a retrieval-augmented knowledge layer, with robustness training that bridges the two, consistently outperforms either approach alone in domains where evidence exists.
One condition that applies across all paths: Before investing in any training infrastructure, run context engineering experiments. A frontier model with a well-crafted system and prompt, dynamic context construction will often clear 80-90% of the quality bar at zero infrastructure cost. The teams that begin fine-tuning when the problem is a prompt engineering issue are paying a 10-50x premium for a solution they did not need.
The Reframe
The question engineering teams have been asking is: RAG or fine-tuning?
The question they should be asking is: retrieval for what you know, behavioural fine-tuning for how you act, robustness training for how you read.
These are three different problems. They have three different ROI profiles, three distinct data requirements, three distinct failure modes, and three distinct evaluation criteria. Collapsing them into a binary choice has been costly — not because teams chose the wrong option, but because the binary framing made the three-layer architecture invisible.
Your model doesn’t fail because it doesn’t know enough. It fails because nobody taught it how to read the imperfect retrieval output your RAG system will inevitably deliver. That is the Layer 3 problem, and it is the one the RAG versus fine-tuning debate has been most successful at obscuring.
The practical summary is blunt: build retrieval first, because FineTuneBench proves commercial APIs cannot reliably inject dynamic knowledge into weights. Add robustness training second, because DRAG proves that even excellent retrieval degrades reasoning performance without a trained generator. Add behavioural fine-tuning third, because this is the problem it is actually solves well. Validate every LoRA run with reduce_intruder_dimension and Noise Sensitivity measurement, because these are the failure modes the research has identified, and the tooling to address them already exists.
References
- arXiv 2411.05059 — FineTuneBench: How well do commercial fine-tuning APIs infuse knowledge into LLMs?
- arXiv 2410.21228 — LoRA vs Full Fine-tuning: An Illusion of Equivalence
- arXiv 2403.10131 — RAFT: Adapting Language Model to Domain Specific RAG
- arXiv 2310.01558 — Making Retrieval-Augmented Language Models Robust to Irrelevant Context
- arXiv 2401.08406 — RAG vs Fine-Tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
- arXiv 2502.09977 — LaRA: Benchmarking Retrieval-Augmented Generation and Long-Context LLMs
- arXiv 2401.05856 — Seven Failure Points When Engineering a Retrieval Augmented Generation System
- hiyouga/LLaMA-Factory — Unified fine-tuning framework (40K+ stars)
- huggingface/peft — Parameter-Efficient Fine-Tuning library (includes reduce_intruder_dimension)
- explodinggradients/ragas — RAG evaluation framework with Noise Sensitivity metric
- langchain-ai/langchain — Production RAG pipeline infrastructure (90K+ stars)