
Introduction
As organisations increasingly rely on data to drive decisions, ensuring that data is interpreted consistently across teams and tools has become a growing challenge. Different definitions, duplicated logic and fragmented governance often lead to conflicting insights and reduced trust in analytics. The semantic layer emerged to solve these issues by creating a shared governed definition of business meaning that connects raw data with its consumers, including people and increasingly AI systems. This article explores the evolution of the semantic layer, the challenges it addresses and why it is emerging as a critical foundation for AI-driven analytics.
What is a Semantic Layer?
A semantic layer is a logical abstraction that sits between underlying data platforms (such as relational databases, data warehouses and data lakes) and downstream consumption layers, including BI tools, dashboards and analytical applications. It defines a canonical representation of data by mapping physical schemas (tables, columns, joins) to business-level constructs such as metrics, dimensions and relationships.
By encapsulating complex transformations, join logic and calculation rules, the semantic layer decouples data consumers from the underlying storage and modelling details. This allows users to query data using consistent, business-oriented definitions without needing to understand source-specific schemas or write low-level query logic.
Additionally, it enforces data access controls and security policies, establishing a governed framework for data consumption. It exposes a consistent interface for analytical tools and applications, while supporting data governance and preserving end-to-end data lineage.
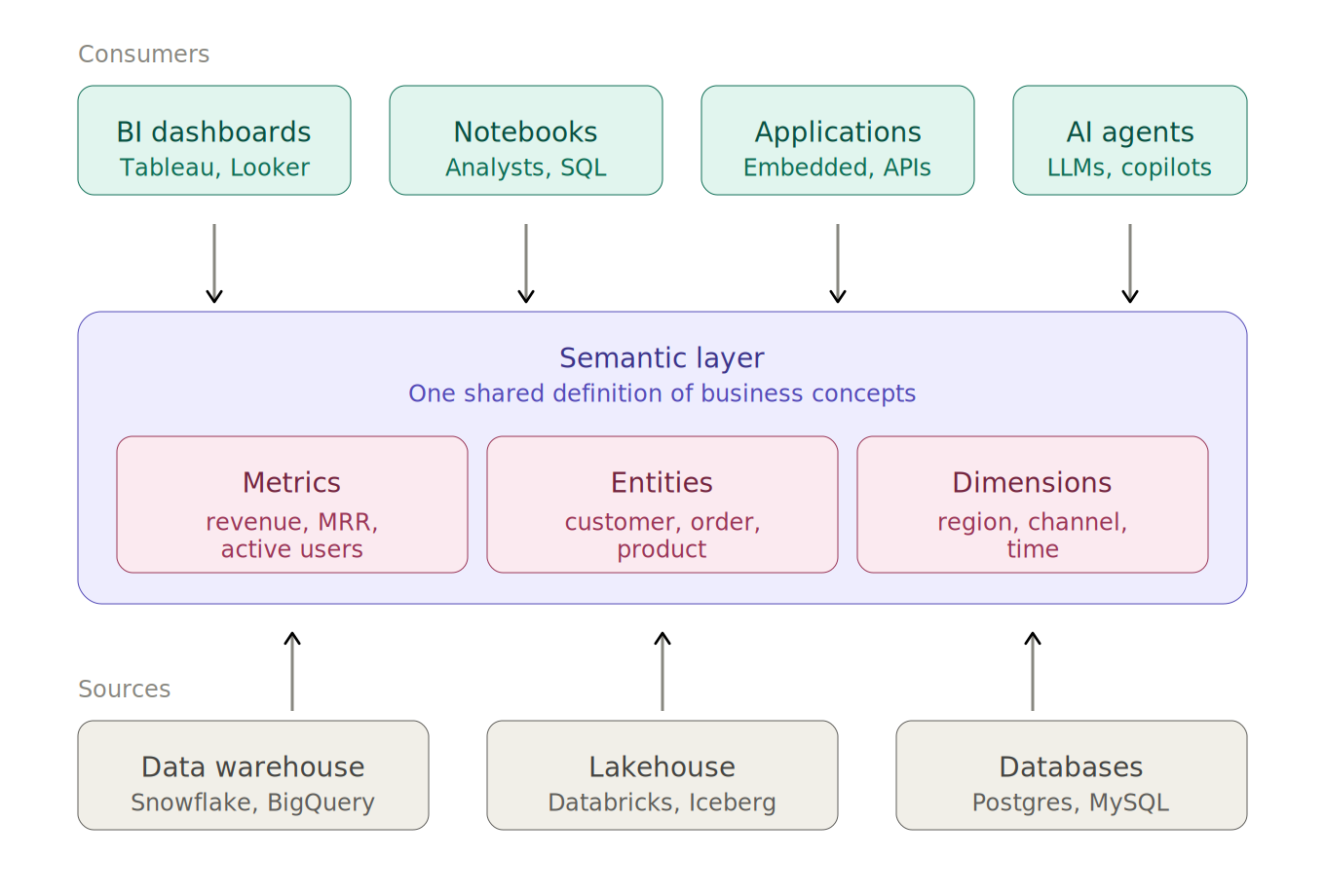
History and Evolution of the Semantic Layer
Pre-2000: Foundations
The roots of the semantic layer date back to the 1970s and 1980s, when the rise of relational databases created a need for business-friendly abstractions over increasingly complex data structures. These ideas matured in the 1980s and 1990s with the emergence of data warehousing, Ralph Kimball’s dimensional modelling approach, still widely used today and OLAP cubes, which enabled multidimensional analysis across dimensions such as time, product and geography.
In 1990, BusinessObjects formalised the modern semantic layer with its pioneering “universe” concept, an abstraction that translated complex database schemas into business-friendly terms. Yet despite these advances, accessing and interpreting data still required considerable technical expertise and business knowledge.
2000–2010: Enterprise BI
During the 2000s, platforms such as BusinessObjects, Cognos, Hyperion and MicroStrategy made semantic layers a standard component of enterprise BI. They enabled centralised metric definitions, governed reporting and early self-service analytics through caching and pre-aggregation. However, these systems were tightly coupled to specific BI tools and remained largely controlled by centralised IT and BI teams.
2010–2020: Fragmentation
The rise of self-service BI tools such as Tableau, Power BI, Looker and Qlik shifted analytics toward decentralised usage. This improved speed and accessibility but led to fragmented metric definitions, duplicated business logic and inconsistent reporting across teams.
As a result, similar metrics were often implemented independently across dashboards, SQL queries and spreadsheets, creating conflicting versions of KPIs. Organisations responded by investing in data governance programmes and centralised analytics functions to restore consistency and trust in reporting.
2020–Present: Revival + AI
Since 2020, the semantic layer has re-emerged as a foundational component of the modern data stack. Tools such as dbt, Cube, AtScale and MetricFlow have decoupled semantic definitions from BI tools, enabling reuse across dashboards, embedded analytics and data applications.
More recently, the rise of generative AI has accelerated this trend. Large language models require structured business definitions to generate accurate and trustworthy analytical outputs, making governed semantic layers increasingly important as a shared source of business meaning across systems. As a result, the semantic layer is evolving from a BI abstraction into foundational infrastructure for AI-driven analytics.
Challenges Without Semantic Layers
As modern data ecosystems grew in complexity, organisations realised that simply centralising data did not automatically produce consistent or trustworthy analytics. Without a shared semantic layer, business logic became fragmented across reporting tools, notebooks and operational applications. Although this decentralisation improved flexibility and speed, it also weakened consistency, governance, interoperability and organisational trust in data.
Metric Inconsistency
A common issue is the lack of consistent definitions for core business metrics across teams and tools. Metrics such as revenue, customer churn, active users, or conversion rates are often implemented differently depending on the dashboard, department, or analytical tool being used.
For instance, “revenue” may be calculated differently depending on the context: finance teams typically rely on realised or invoiced revenue, while growth or product analytics teams may include bookings or subscription commitments. Similarly, with “active users,” one dashboard might define an active user as anyone who logged in within the past 30 days, while another might only count users who performed a meaningful action within a 7-day window.
These discrepancies are often not intentional but instead emerge from practical constraints. Different teams build metrics independently in SQL, BI tools, or spreadsheets, each optimised for a specific use case or timeframe. Over time, small differences in filters, time windows, attribution logic, or aggregation rules compound into significantly different outcomes for the same KPI. As a result, stakeholders are often exposed to conflicting versions of “truth,” which undermines confidence in reporting and makes cross-functional alignment significantly more difficult.
Duplicated Logic
Without a shared semantic abstraction, analysts and data practitioners often re-implement the same business logic across dashboards, notebooks, spreadsheets and ad hoc SQL queries, each adapted to a specific use case or reporting context.
This duplication creates long-term maintenance challenges. When upstream schemas change, like renaming a column, updating a relationship, or modifying a transformation, those changes have to be manually propagated across every downstream implementation that relies on that logic and that rarely happens consistently.
Over time, assets that were meant to represent the same underlying business logic start to drift apart. The result is a fragile analytics environment, where reliability depends less on a shared model and more on the ongoing effort required to keep scattered definitions in sync.
Governance Fragmentation
Governance becomes increasingly difficult when business definitions, access controls, lineage information and data quality rules are managed independently across multiple platforms and analytical tools. In these environments, organisations often struggle to enforce compliance policies uniformly, or apply security rules such as row-level access control across all systems consuming the data.
Traceability is also weakened. When business logic is embedded directly in dashboards or SQL queries, it becomes difficult to determine how a metric was constructed, which datasets were used, or whether the correct transformations were applied. This reduces auditability and makes both debugging and regulatory compliance more complex.
Data quality management suffers similarly. Validation checks and monitoring rules are frequently implemented separately within individual workflows instead of being centrally standardised. As a result, teams may rely on different assumptions, thresholds, or freshness criteria for the same datasets, allowing inconsistencies and data issues to remain undetected until they surface through conflicting reports or operational problems.
In the long term, the absence of centralised governance creates a fragile analytics ecosystem in which consistency, security and reliability rely heavily on ongoing manual coordination across teams and tools.
AI and Semantic Misalignment
The rise of AI-driven analytics and Text-to-SQL systems has amplified existing governance challenges by increasing both their scale and speed of propagation.
Large language models are highly effective at translating natural language into syntactically correct SQL, but they do not understand business semantics: the organisational meaning behind metrics, relationships and definitions that determine how data should be interpreted.
Instead, these systems learn statistical patterns across language and schema structures. This allows them to generate plausible queries based on naming conventions and structural similarity, without any guarantee that the result aligns with actual business logic. As a result, AI systems can produce queries that execute correctly while returning misleading insights.
Without a governed semantic layer, an AI system may:
- apply inconsistent definitions of key metrics such as revenue or churn,
- infer incorrect joins based on naming similarity,
- aggregate data at the wrong level of granularity,
- confuse similar entities across domains,
- or ignore embedded governance constraints.
These errors are semantic rather than syntactic: the query runs successfully, but may not fully capture the intended meaning. In AI systems, this can sometimes be easy to overlook, since coherent explanations and working SQL naturally inspire confidence. As AI becomes more widely adopted across enterprise analytics, having a well-defined semantic layer becomes increasingly valuable, ensuring that everyone, human or AI, is working from the same shared understanding of the business.
Semantic Layers as Infrastructure for AI
As organisations increasingly integrate large language models into analytics workflows, the role of the semantic layer is undergoing a fundamental shift. What was traditionally viewed as a mechanism for standardising business definitions in BI systems is becoming a critical infrastructure layer for AI-driven data interaction.
Unlike traditional BI tools, which rely on predefined models, dashboards and curated queries, LLM-based systems generate analytical logic dynamically from natural language. This dramatically increases flexibility and accessibility, but also introduces greater sensitivity to ambiguity in business meaning and contextual interpretation. In this environment, the semantic layer is no longer limited to ensuring consistency across reports; it becomes part of the infrastructure through which AI systems interpret enterprise data.
A governed semantic layer changes how AI interacts with analytical systems. Rather than relying on schema inference, table naming conventions, or implicit prompt context, AI systems operate over standardised business abstractions such as customer, revenue, churn, or conversion, each backed by governed definitions, validated relationships and approved aggregation logic.
This distinction becomes increasingly important as AI systems move from exploratory analytics into operational workflows such as automated reporting, embedded analytics and decision-support systems. In these environments, inconsistencies in interpretation are no longer isolated analytical errors; they become systemic risks embedded directly into automated decision processes.
The semantic layer therefore functions as a control plane for AI-driven analytics. It governs how business meaning is represented, ensures consistency across human and machine consumption and provides the structured context required for reliable query generation at scale.
It also improves reproducibility and auditability in AI-generated analytics. Because definitions, joins, hierarchies and aggregation rules are centrally managed, organisations can trace how metrics were produced, validate the logic used and reproduce analytical outputs consistently across systems and time.
In this sense, the semantic layer becomes part of the infrastructure that enables AI systems to operate safely, consistently and predictably within an organisation’s data ecosystem.
Example: AI Querying Through a Semantic Layer
Consider the question:
“What was enterprise customer churn in EMEA last quarter compared to the previous year?”
Without a semantic layer, the AI must infer:
- definition of enterprise customer,
- churn calculation logic,
- geographic boundaries of EMEA,
- correct joins,
- and aggregation level.
Suppose the only available data consists of the following raw tables:

With these raw tables, the AI might generate a query like the following. The SQL is syntactically valid, but it is based on several hidden assumptions:
-- ⚠️ AI-generated without a semantic layer
-- Ambiguous: "enterprise" = ARR > 50k? Or plan_type = 'enterprise'?
-- Ambiguous: "churned" = end_date IS NOT NULL? Or status = 'cancelled'?
-- Ambiguous: "EMEA" = a hardcoded list of country codes? Which ones?
-- Ambiguous: "last quarter" = calendar Q? Fiscal Q? Based on what timezone?
SELECT
COUNT(DISTINCT c.id) AS churned_customers_this_period,
COUNT(DISTINCT c2.id) AS churned_customers_prev_year
FROM customers c
JOIN subscriptions s ON c.id = s.customer_id
JOIN regions r ON c.country_code = r.country_code
LEFT JOIN customers c2 ON c2.country_code = r.country_code
AND c2.arr > 50000
AND c2.last_invoice_date < DATE_SUB(NOW(), INTERVAL 2 QUARTER)
WHERE
c.arr > 50000 -- "enterprise" assumption
AND s.status = 'cancelled' -- "churn" assumption
AND r.region_label = 'EMEA' -- region label might vary: 'emea', 'Europe/ME/Africa'?
AND s.end_date BETWEEN
DATE_SUB(NOW(), INTERVAL 1 QUARTER)
AND NOW();A governed semantic layer removes this ambiguity by providing standardised definitions:
- canonical churn logic,
- consistent customer segmentation,
- governed geographic hierarchies.
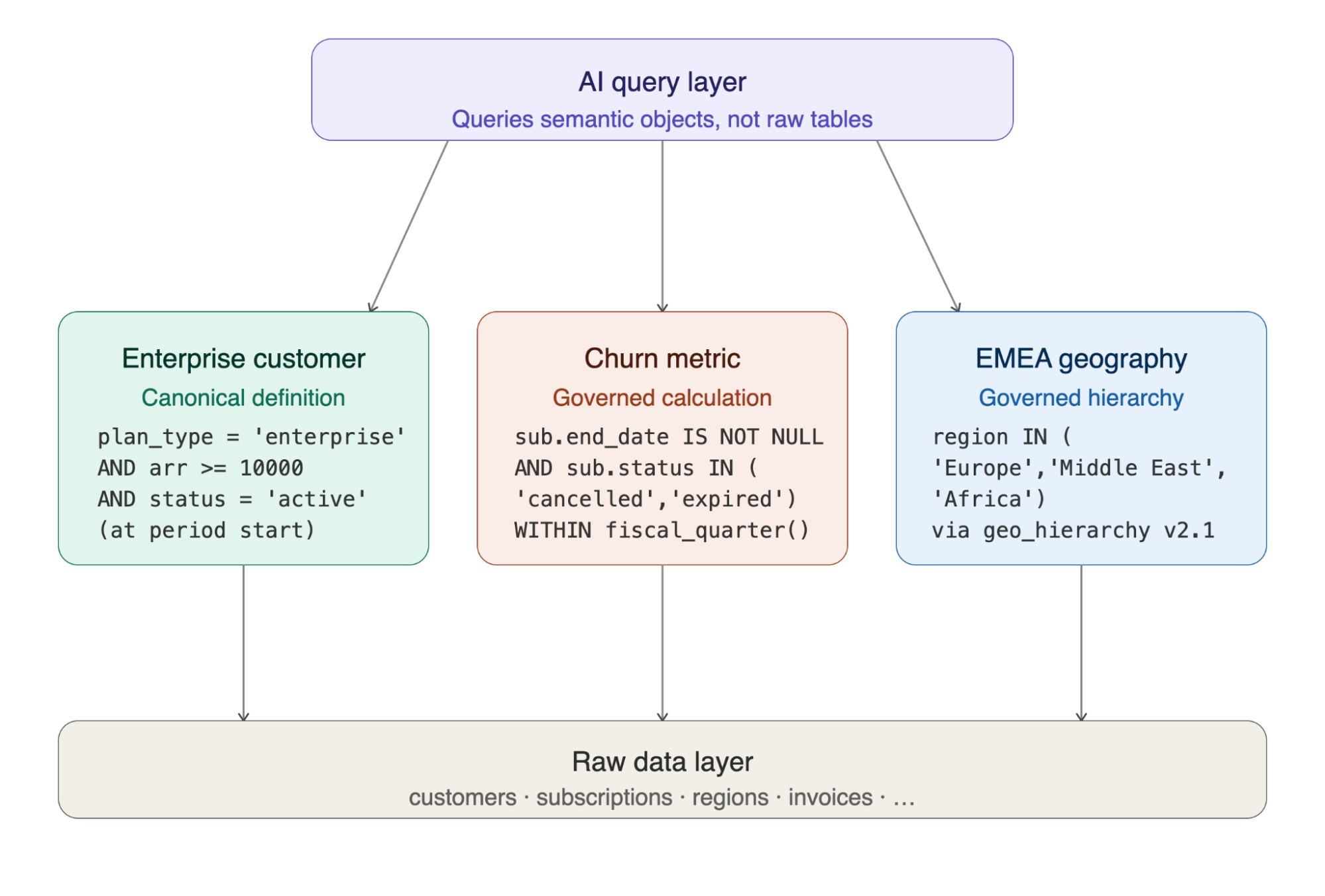
Now, instead of reasoning over raw tables, the AI generates queries against a structured model of business meaning.
-- ✅ AI-generated over the semantic layer
-- No business logic assumptions needed — all resolved by the semantic model
SELECT
geo.region AS geography,
date_spine.fiscal_quarter AS period,
COUNT(DISTINCT churn.customer_id) AS churned_enterprise_customers
FROM semantic.churn_events AS churn -- governed: cancelled OR expired
JOIN semantic.enterprise_customers AS ent
ON churn.customer_id = ent.customer_id -- governed: plan+ARR+status definition
JOIN semantic.geo_hierarchy AS geo
ON ent.country_code = geo.country_code
AND geo.region_group = 'EMEA' -- governed: canonical region membership
JOIN semantic.fiscal_calendar AS date_spine
ON churn.event_date BETWEEN
date_spine.quarter_start AND date_spine.quarter_end
WHERE
date_spine.fiscal_quarter IN (
fiscal_quarter_offset(0), -- current quarter
fiscal_quarter_offset(-4) -- same quarter, prior year
)
GROUP BY
geo.region,
date_spine.fiscal_quarter
ORDER BY
date_spine.fiscal_quarter,
geo.region;This reduces ambiguity, improves consistency and makes AI-driven analytics scalable in enterprise settings.
Modern Semantic Layer Solutions and Tradeoffs
Today, semantic layers are implemented through a range of architectural approaches that differ in where business logic is defined, how tightly they are coupled to downstream tools and the degree of centralisation they provide. While the goal across all approaches is to standardise metrics, definitions and relationships, the implementation patterns vary significantly across the modern data stack.
These approaches can broadly be grouped into three categories:
- BI-embedded semantic layers,
- transformation-layer semantic models,
- and standalone or headless semantic layers.
BI-Embedded Semantic Layers
The earliest and still widely used approach is the BI-embedded semantic layer, where business definitions are defined directly within a business intelligence tool. Platforms such as Looker, Microsoft Power BI and Tableau provide built-in semantic modelling capabilities that allow users to define measures, dimensions, hierarchies and relationships within the BI environment itself.
In this model, semantic logic is tightly coupled to the reporting layer. This enables strong integration between data modelling and visualisation, allowing business users to interact with consistent metrics within a single tool.
However, because the semantic layer is embedded within a specific BI platform, definitions are often not easily reusable outside that ecosystem. As organisations adopt multiple BI tools or extend analytics into applications, APIs, or AI systems, semantic logic may need to be re-implemented or duplicated across environments.
Transformation-Layer Semantic Models
A second approach embeds semantic logic within the data transformation layer, typically using modern ELT workflows. Tools such as dbt allow teams to define reusable models, metrics and transformations in SQL closer to the warehouse layer.
Here, business logic is materialised during data transformation rather than within BI tools. This shifts semantic management toward engineering workflows, often improving version control, testing and consistency across downstream consumers.
While this approach improves standardisation across analytics tools using the same transformed data, semantic definitions often remain tied to specific transformation frameworks or warehouse-centric designs. This can limit their direct reuse in broader application or AI-driven contexts.
Headless or Standalone Semantic Layers
A more recent pattern is the emergence of headless or standalone semantic layers. These systems decouple semantic definitions from both BI tools and transformation pipelines, exposing them as an independent service layer accessible via APIs or query interfaces.
Platforms such as Cube, MetricFlow and AtScale fall into this category. In this model, semantic definitions are centrally managed and consumed across BI tools, embedded analytics, operational applications and AI systems.
This approach is designed to support multi-consumer environments where the same business definitions must be shared across heterogeneous systems. It is particularly relevant in modern architectures where analytics is no longer limited to dashboards, but also includes embedded analytics, data products and AI-driven interfaces such as Text-to-SQL systems. However, this architecture introduces additional complexity in deployment and governance, as it requires maintaining a separate semantic service layer alongside existing data infrastructure.
Tradeoffs
Across these approaches, the primary distinction is not only where semantic logic is defined, but how semantic authority is distributed across the stack. Each model represents a different answer to the question of where business meaning should be governed and how widely it should propagate across tools, pipelines and AI systems.
BI-embedded semantic layers concentrate semantic authority inside a single BI tool, optimising for simplicity and tight integration, but limiting reuse beyond that environment.
Transformation-layer models shift semantic authority into data pipelines, improving engineering control and consistency, but remaining largely warehouse-centric in scope.
Headless semantic layers externalise semantic authority into a dedicated service layer, maximising reuse and consistency across systems, including AI-driven applications, but introducing additional operational and governance complexity.
Conclusion
As data consumers increasingly include autonomous systems as well as people, the semantic layer is best understood not as another tool in the stack, but as the control plane through which business meaning is defined, governed, and shared. As AI becomes a routine participant in analytics, that shared understanding is what distinguishes data that is merely accessible from data that can be trusted.
Author:

Alessia Casagrande is an experienced Senior Data Engineer with a diverse background of working with companies ranging from startups to large enterprises. She is passionate about all things data, from building robust platforms to conducting in-depth analytics, and is always curious to explore the latest technologies in the field.