
There is a version of AI assisted development that sounds appealing until you live with it. You hand a task to an AI agent, walk away and come back to a finished feature. No interruptions, no approval prompts and no waiting. Pure throughput.
There is also a version where you approve every single tool call. Every file read, every bash command and every edit. The agent is technically running but you are still doing all the cognitive work. You have just moved the bottleneck from your keyboard to a confirmation dialog.
Neither of these matches how production agentic development actually works at scale.
Anthropic published empirical data on real world agent deployments in February 2026. 80% of agent tool calls already have at least one safeguard in place and 73% have some form of human involvement in the loop.[^1] The question is not whether humans should be involved. It is where and how that answer changes as trust is established.
The Control Problem Is Not Binary
The AI safety community has converged on a three tier model for describing human involvement in automated systems:[^2]
- Human-in-the-loop (HITL): Human must approve before the agent executes. The human is a prerequisite to action, not a reviewer of it.
- Human-on-the-loop (HOTL): Agent acts autonomously, human monitors and can intervene. The human is present but not blocking.
- Human-in-command (HIC): Agent is advisory only. Humans retain unconditional decision authority.
Most engineering teams treat oversight as binary. Either the agent runs free or it waits at every step. Production reality is a spectrum. The appropriate tier depends on two variables: the reversibility of the action and the degree of trust established through demonstrated agent behaviour.
Only 0.8% of agent actions in Anthropic’s production dataset are irreversible.[^1] That is the category where HITL gates matter unconditionally. For the other 99.2%, the question is whether the action falls within a scope the agent has reliably handled before.
Effective oversight, as Anthropic frames it, is not about prescribing specific interaction patterns, it is about ensuring humans can monitor and intervene when it matters.[^1] A gate at a low risk, reversible action creates friction without safety benefit. A missing gate at an irreversible boundary is the actual failure mode.
How do you build the structure that makes the right gates obvious and why a generalist agent makes this problem hard: a single agent handling a full story, plan, implement, test, commit and push gives you no structural answer. The session is an unbroken stream. No phases, no handoffs, no transitions between responsibilities. The human faces a binary, watching everything or watching nothing.
The 2025 taxonomy of multi agent architectures identifies three dominant topologies:[^3]
- Chain: Sequential handoffs across a fixed agent sequence, each agent passes a standardised artifact to the next (MetaGPT’s SOP model)
- Star: A central orchestrator dispatches to specialist agents and aggregates results, the dominant pattern in Claude Code multi agent workflows
- Mesh: Decentralised, dynamic peer-to-peer agent interaction
Topology matters for oversight. Chain and star architectures produce explicit handoffs. Defined moments where one agent’s output becomes another agent’s input. These handoffs are structurally equivalent to phase gates: Robert Cooper’s Stage-Gate methodology, building on NASA phased review processes from the 1960s, defines a gate as a formal Go/Kill/Hold decision point where a review team assesses a work product before it advances.[^4] The multi agent handoff is the same mechanism at a different layer of abstraction.
Without role separation, there are no handoffs. Without handoffs, there are no gates. Without gates, human oversight becomes constant vigilance which is not oversight, it is babysitting.
What Role Separation Actually Changes
A coordinating session that delegates to specialist agents, an architect reviewer, a QA agent, a security reviewer each with a defined scope and a clear handoff condition is a Star topology with enforced role boundaries. The published taxonomy identifies four canonical role types:[^3]
- Manager/Controller: delegates, aggregates results
- Worker: executes domain tasks within bounded scope
- Verifier: critiques outputs from an independent context, separate system prompt, no prior exposure to the work being reviewed
- Supervisor/Reviewer: safety critique, unconditional override authority
No agent approves its own work. The Verifier role exists precisely because a Worker that reviews its own output has no independent perspective.
The reliability case for this structure is empirical. The MAKER framework which separates Worker and Verifier roles explicitly reported near zero error accumulation across extended reasoning chains.[^3] Research on MetaGPT and ChatDev, both of which enforce explicit role boundaries and standardised handoff artifacts, showed a 30% reduction in bugs compared to single agent baselines.[^3]
In Claude Code terms: the Agent tool spawns each specialist with a scoped system prompt. TaskCreate and TaskUpdate maintain shared state across handoffs so each agent receives exactly the context it needs and nothing more. Hooks encode hard limits at the HIC tier, enforced without human attention and without agent negotiation. We have codified these patterns into an internal framework that makes them activatable across different codebases without rebuilding the scaffolding each time but the underlying mechanics are native Claude Code.
The effect on human oversight: each handoff is an inspection point. The architect reviewer completes its analysis before a line of code is written. The QA agent runs its suite before a commit lands. The security reviewer scans before anything reaches a branch. The human does not watch every step, they are present at the transitions that connect phases, where independent judgment adds value.
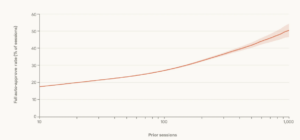
Figure – 1 Claude Code Auto Approve Rate By Experience
Auto-accept rate vs. practitioner experience: as experience with agent workflows grows, practitioners auto-approve a higher share of tool calls reflecting trust that has been calibrated through repeated exposure rather than optimism.
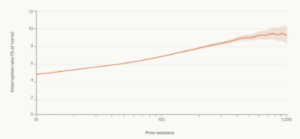
Figure – 2 Claude Code Interruption Rate By Experience
Intervention rate vs. practitioner experience: more experienced practitioners intervene more selectively, fewer total interruptions, but concentrated at structurally significant boundaries (phase transitions and irreversible actions).
What That Looks Like in a Real Session
In a recent story implementation on one of our projects, a developer kicked off the session with a brief: build an HTTP endpoint, wire up the tests and push to branch. The agents handled the full execution loop, implementing the endpoint, running 58 tests, resolving a merge conflict and pushing three times to the remote. From the outside, pure automation.
Inside the session, three things happened at three different tiers of the control model.
When the QA agent completed its work and handed off a mock client for the test suite, that transition was where a human looked. The mock was missing an auth header, a subtle omission that would have produced passing tests against a broken contract. The catch happened at a handoff boundary. The role structure created the inspection point, the human used it. This is a HITL gate at a phase transition exactly where it belongs.
Later, a cleanup step attempted a broad recursive delete. A hook blocked it, requiring individual file removal instead. No human attention required. This is HIC, infrastructure enforced the irreversibility constraint unconditionally.
The test suite itself ran in HOTL mode, agents executed and a human monitored the aggregate result without approving each individual test invocation.
This is the pattern Anthropic’s data describes: experienced practitioners auto-approve more frequently as trust is established, but interrupt more often at the moments that matter.[^1] The intervention is not random, it is calibrated to the structural boundary where independent judgment adds value.
Three Starting Points – Not a Recipe
These patterns are not universal rules. The right tier for any action class depends on your codebase, your agents’ demonstrated reliability and the reversibility profile of the specific operation. What follows is where experienced practitioners tend to start, not where they always end up.
Start by mapping irreversibility, not frequency.
Anthropic’s production data puts irreversible actions at 0.8% of agent tool calls.[^1] Your project’s list will be specific, push to a production branch, schema migration, external API call with side effects, file deletion outside the working tree. These are unconditional HITL gates which are mandatory regardless of established trust since the recovery cost is high and the agent’s error rate is not zero. Map these first. Everything else is a candidate for HOTL or lower friction.
Scope each agent’s role so handoffs have clear semantics.
Verifier agents should not write code. A QA agent should not decide whether a feature ships. When agents have defined roles, the human reviewing a handoff has a bounded mental model, what to check and what to trust. In Claude Code terms, separate system prompts per role, scoped tool access, CLAUDE.md rules that encode role constraints as enforced behaviour rather than documented convention. The handoff artifact that one agent produces for the next should be explicit enough that a human can assess it in under two minutes.
Build the HIC layer before the HITL layer.
Hooks, permission settings, and CLAUDE.md rules operate at the HIC tier unconditionally and cannot be overridden by the agent. A hook blocking recursive deletes runs without human attention and without agent negotiation. Every boundary encoded at HIC is a boundary your human oversight does not need to cover at runtime. Build this layer first. It determines where HOTL monitoring can safely operate and where active HITL gates are actually needed.
The goal is not to achieve oversight correctness from day one. It is to build the structure that makes oversight progressively cheaper as trust is established: moving from HITL toward HOTL at the action classes where reliability is demonstrated, while keeping irreversibility gates unconditional. In our own work, this progression from initial heavy oversight toward calibrated autonomy is what eventually prompted us to formalise it into something reusable.
The question “when should your agent ask for permission?” does not have a static answer. It has an architectural one and the architecture evolves as trust does.
Role based agents create the structure, defined scopes, explicit handoffs and natural inspection points. The three-tier model (HITL, HOTL, HIC) provides the vocabulary, which gates are mandatory, which can shift toward monitoring, which belong in infrastructure. The practitioner provides the judgment, which transitions in this codebase, with this agent’s demonstrated behaviour warranting active review and when earned autonomy is the better choice.
The teams that get this right are not the ones who approve everything or the ones who let everything run. They are the ones who are deliberate about which tier applies at each boundary and who adjust as the evidence comes in.
At Zartis, we work with teams building and operating agentic development workflows across client projects. If you want to explore how role-based architectures and structured oversight could work in your context, get in touch.
Author:
Bugra Sitemkar is a software engineer at Zartis specializing in Microsoft Stack and Azure. He’s passionate about applied AI and building GenAI tooling. He occasionally moonlights as a hardware hacker.
Sources
- [^1]: Measuring Agent Autonomy — Anthropic, 2026-02-18 — https://www.anthropic.com/news/measuring-agent-autonomy — local: research/claude-code-personal-experience/hitl-patterns-research.md
- [^2]: Human-in-the-Loop in AI Workflows — Zapier / Juliet John, 2025-11-12 — https://zapier.com/blog/human-in-the-loop/ — local: research/claude-code-personal-experience/hitl-patterns-research.md
- [^3]: Agentic AI Architectures, Taxonomies, and Evaluation — arXiv:2601.12560, 2025 — https://arxiv.org/html/2601.12560v1 — local: research/claude-code-personal-experience/hitl-patterns-research.md
- [^4]: Phase Gate Process — Smartsheet, 2024 — https://www.smartsheet.com/phase-gate-process — local: research/claude-code-personal-experience/hitl-patterns-research.md
Figure – Sources
1,2 – https://www.anthropic.com/news/measuring-agent-autonomy