Table of Contents
Preface
How to structure software teams to enable optimal collaboration and improve ROI by removing sources of friction.
Why manage dependencies between squads?
Why dependencies are risky, expressed mathematically.
Common mistakes
What are the biggest mistakes made when managing dependencies between squads?
Managing the points of failure
The biggest problems caused by excessive points of failure & how you can solve these issues.
Dividing software squads
The biggest problems caused by dividing software squads inefficiently & how you can solve this issue.
Scalable team structures
Causes of unscalable team structures with isolated squads & how you can solve this issue.
Key takeaways
The main lessons derived from the suggested solutions to improve a development team's structure.
Preface
As a technology company, the success of your product development and by extension your business depends in no small part on how you structure and continuously optimise your development teams.
In this whitepaper, we will talk about the most common mistakes that lead to excessive dependencies in the SDLC and how to avoid them.
To be clear, we are not suggesting that all dependencies are bad. Lean, agile teams create value streams by transferring knowledge and enabling other squads to build upon them.
FIND THE ANWERS
How should I structure software teams to enable optimal collaboration and improve ROI by removing sources of friction?
Why manage dependencies between squads
The logic is simple. The more dependencies you have, the more likely you are to have a hitch. Here is why dependencies are risky, expressed mathematically:
A -> f (A) = B -> f’ (B) = C -> … -> Z
Let’s say each letter represents what a team needs, each function represents a team’s work, and the output is a letter that is used as input by another team. In the case above, Team f(A) needs A to produce B, then without the B, team f'(B) can’t produce C, which is what team f'(C) needs, and so on.
IF the average probability of each team delivering their part without a hitch is 90%, and there are 10 steps in your existing processes, the aggregate probability of a hitchless success is less than 35% (.9^10 * 100).
And just to be clear, “hitchless” in this context means deliverables are exactly what’s expected, and they are delivered on time. In real life, that probability maxes out at around 70% for super-performant teams, and 50% is the more likely average. The aggregate probability of a hitchless 10-step process would drop to 0.09% with those odds. That is as probable as flipping a coin 10 times in a row and getting heads each time!
Are you willing to bet your company’s success on those odds?
Common mistakes
What are the biggest mistakes in managing dependencies between squads?
Excessive number of points of failure
Can you identify the different points of failure in your processes and minimize them?
Dividing software squads inefficiently
What are you dividing squads based on? Functionalities? Skills? SDLC? Business domains?
Keeping the same structure as the company grows
Is there room for change and innovation in your team structure and processes?
Managing the points of failures
The problem: Excessive number of points of failure
Companies and leaders who try to apply proven approaches to development team structure usually encounter problems in the delivery pipelines. Usually, this is because they fail to foresee the bottlenecks and processes that may create friction.
The solution:
Dependency coordination should be done in a planning session, preferably with all the teams present through at least one squad member who can represent the rest of the team. It is essential for teams to identify the dependencies themselves and take ownership. By having all teams represented, it becomes easier to identify these dependencies before it is too late.
For example, when team A has a dependency on team B, it is team A’s responsibility to create clear requirements, and set clear expectations for team B. In return, Team B is required to acknowledge the dependency (if within their capacity) and deliver by the agreed time. Because both squads agree on what is to be delivered and when, they can minimize delays. This mutual agreement, especially if documented, imprints mutual accountability and acts as a contract of sorts.
In order to enable this communication, try to move away from silos of information, where only the managers are notified about specific needs. The expectations should be made public so that teams are empowered to identify dependencies between other teams and themselves.
This allows teams to do a lot of the heavy lifting, and coordinate with each other. It also leaves no need for bottlenecks in the form of managers. Managers are there to facilitate, but the teams know their domain the best and can help shape the results required from the other teams in order to unblock themselves.
Dividing software squads
The problem: Dividing software squads inefficiently
In many companies, team boundaries are defined by the life-cycle of delivery to customers, resulting in an assembly-line setup. By stacking up processes, companies lose the flexibility to progress on all fronts at all times and fall into a waterfall development trap.
The solution:
Dividing squads based on domain boundaries is a good starting point to minimize dependencies. Each domain boundary is called a bounded context.
Bounded Context: The boundary within a domain where a particular domain model applies. Within each bounded context, we create a shared language through conversations between the business specialists and engineers. [1]
Think of them as focused delivery squads within a business domain. In an ideal scenario, each squad would handle a single bounded context – though it is possible for a squad to handle multiple contexts at once, or two squads to work on a complex or big part of the system together.
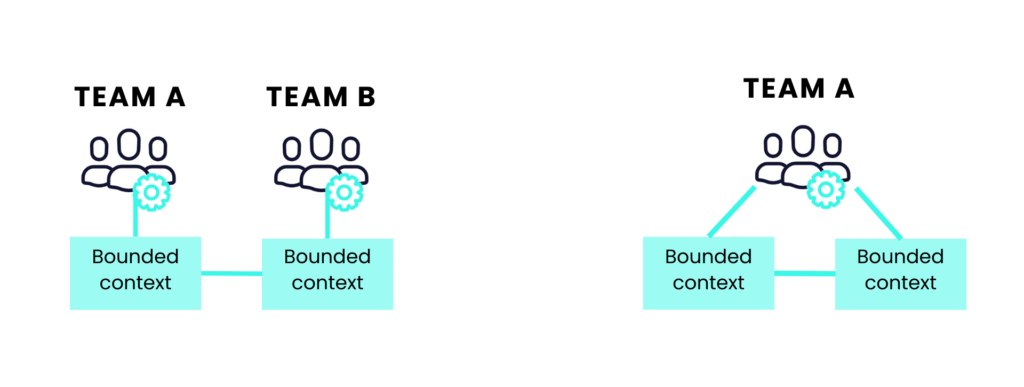
It is crucial for teams dealing with multiple bounded contexts not to mix the language and processes between each other and blur the boundaries. It is a considerable mental challenge to switch between contexts and individual models of each.


How to identify the right domains?
To utilize bounded contexts properly and define teams, the first step would be to create a domain model of the organization. A domain model can be a static diagram explaining the structure of an organization through visualizing real-world business units (domains), their operations, and the relationships & dependencies between those units.
In combination with the domain model, Domain-Driven Design (DDD) makes it easier to assign parts of the software to different squads based on bounded contexts. Different applications, different end-users of the same application, or distinct functionalities can be used to create bounded contexts.
Within a bounded context, each squad can take ownership of its model and increase autonomy. They can test in isolation, since teams have a clear vision of who their customers are and can receive their own feedback metrics. Studies by Nicole Forsgren Ph.D., Jez Humble, and Gene Kim (2018) have shown that the strongest predictors of continuous delivery performance and successful organizational scaling are loosely coupled teams enabled by loosely coupled software architecture. [2]
This makes the bounded context a very important pattern for companies that are scaling or want to accelerate their software delivery.
Example of a bounded context:
Let’s say your defined bounded context is finance reporting.
Make sure to enable the relevant team to have full ownership of the domain model, data model, any of the business logic (there can be one or more microservices) and the presentation layer (SPA, microfrontends). This enables the team to be self-sufficient and introduce any changes into the system to achieve the objectives. At the same time, their dependencies are limited to a minimum because they have all the people and all the components within one squad and can plan their work thoroughly.
Although autonomous, these squads would also have a good overview of how they need to interact with other squads. They might still be asked to expose data points to other bounded contexts and squads (see our first problem in the document).
Scalable team structures
The problem: Keeping the same structure as the company grows
Team structures that work perfectly in the early stages of a company might not necessarily work when the company is growing. Some companies need to change their organizational structure to scale, where others end up with way too many siloed squads and misalignments.
The solution:
Today, most successful and growing teams use lean-agile development methodologies to create and deliver value. However, being agile on its own will not make you scalable. To implement agile at an enterprise level, many companies use the Scalable Agile Framework (SAFe).
In SAFe, the squads are self-organizing and self-managing, which makes them accountable for the deliverables to their specific customer profile and stakeholders. These squads are also expected to address dependencies with other software squads and make sure all parties meet delivery deadlines.
Even if you are not ready to implement SAFe, go through their documentation and see what pieces of that framework work for you. [3]
Invest in an OKR framework that you can use to work with your teams to set up objectives and key results.
OKRs stand for objectives and key results, a goal-setting methodology that can help your team set and track measurable goals. Originally pioneered by John Doerr, this framework pairs the objectives you want to achieve with the key results you’ll use to measure progress—so your goals are tied to your team’s day-to-day work. [4]
There are multiple benefits of using OKRs for engineering teams. Firstly, a clear direction is given. The team is aligned on what their objectives are and how they are going to be measured and assessed. Secondly, it is the team coming up with solutions for the objectives and this creates the sense of ownership and nurtures self-organization. Last but not least, if the objectives are well defined and present real value and aspiration, they create a challenge for the engineering teams. A good challenge drives a lot of engineering teams.
How to enable self-organizing, self-managing squads?
Be a coach and mentor, not a manager.
Provide vision and also the autonomy to take initiative.
Have a product owner & a scrum master in each squad.
Let the teams decide on which stories to implement & how.
Promote decentralized decision making.
Key takeaways
Self-organizing squads
With the help of a product owner and scrum master, you can enable decentralized decision-making and enable teams to set and manage their own OKRs.
Scalable agile framework
SAFe can allow you to apply agile methodologies at an enterprise level and manage roles, collaboration, and the workload at scale.
Information sharing
The expectations should be made public to everyone so that teams can try to identify dependencies they have on other teams and what others depend on them for.
Domain-Driven Design
DDD makes it easier to assign parts of the software to different squads based on bounded contexts.
Managers as facilitators
If the teams are able to identify and address dependencies, then the manager’s role is to facilitate what the teams need to address those. Agenda-setting becomes the team’s responsibility.
Proper planning
Dependency coordination should be done in a planning session, preferably with all the teams participating so dependencies can be identified early on.
Dividing squads based on domainS
Domain boundaries is a good starting point to minimize dependencies. Each defined boundary is called a bounded context. Within a bounded context, each squad can take ownership of its model and increase autonomy.
Do you need help on your transformation journey?
