
In an era increasingly driven by data, access to high-quality, diverse, and representative datasets is critical for building robust analytics and machine learning systems. Yet organizations frequently face barriers such as data scarcity, stringent privacy regulations (e.g., GDPR, HIPAA), and the high cost and complexity of collecting and labeling sensitive information.
Synthetic data generation, which involves producing artificial data that mirrors the statistical properties of real datasets, has emerged as a practical solution to these challenges. It enables organizations to simulate complex scenarios, augment training data, and validate models without exposing sensitive or regulated information.
This approach is gaining momentum across industries. In finance, synthetic data supports compliance-friendly model development in areas like fraud detection and credit scoring. In cleantech, it allows for scenario modeling and predictive analytics where real data may be incomplete, inconsistent, or slow to collect. As companies expand their data-driven strategies, synthetic data is becoming a strategic asset that accelerates development cycles, improves model performance, and ensures privacy by design.
What Is Synthetic Data?
Synthetic data is artificially generated to replicate the statistical properties, relationships, and patterns of real-world data, created using algorithms or models instead of being directly collected from real events. It preserves the structure of actual datasets while eliminating sensitive or proprietary information. By leveraging techniques like simulation, generative models, and statistical methods, synthetic data enables organizations to create tailored datasets that meet specific needs while ensuring privacy and compliance.
Synthetic Data vs. Anonymized and Augmented Data
While synthetic data shares some similarities with anonymized and augmented data, there are important distinctions in their purpose, generation methods, and applications.
Anonymized data is real data that has had personally identifiable information (PII) removed or obfuscated to protect privacy. For example, names, addresses, or social security numbers might be replaced with pseudonyms or deleted entirely. While anonymization helps address privacy concerns, it still relies on real-world data, meaning it might inadvertently expose patterns or associations that can still be re-identified through advanced data analysis techniques (e.g., through re-identification attacks).
Augmented data is real data that has been modified to create variations, typically used to improve the diversity and robustness of machine learning models. Augmentation is commonly applied in domains like image recognition, where transformations (e.g., rotating, flipping, cropping) are used to generate additional examples from existing data. In text and speech processing, augmentation techniques like paraphrasing or noise injection can be used to create more varied training examples.
Understanding these distinctions is crucial because synthetic data provides distinct advantages over anonymized or augmented data, especially in highly regulated industries or when creating datasets where real data is scarce or difficult to obtain.
The importance of Synthetic Data Generation
Compliance with Data Privacy Laws (e.g., GDPR, HIPAA)
Data privacy regulations such as the General Data Protection Regulation (GDPR) in the EU and the Health Insurance Portability and Accountability Act (HIPAA) in the U.S. impose strict rules on how personal data can be collected, stored, and processed. Violations can result in massive fines and reputational damage.
Synthetic data offers a compliant alternative. Since it doesn’t contain personally identifiable information (PII) or real-world records, it generally falls outside the scope of many privacy regulations. However, it’s essential that synthetic data is generated with strong guarantees that it is statistically similar, but not re-identifiable. Privacy-preserving techniques, such as differential privacy, are increasingly being used to ensure synthetic datasets cannot be reverse-engineered.
Overcoming Data Scarcity
Another key benefit of synthetic data is its ability to overcome data scarcity. When collecting real-world data is expensive, time-consuming, or simply not feasible, synthetic data can fill the gaps with realistic, high-quality examples. For instance, in medical imaging, while common conditions like pneumonia or fractures are well-represented, the same cannot be said for rare diseases or uncommon presentations of common conditions. The lack of adequate data for these rare conditions makes it difficult for AI models to reliably detect or diagnose them. Here, synthetic data can bridge the gap by generating realistic images of rare diseases or anomalies, providing the model with the necessary examples to improve its detection capabilities.
Beyond compliance and availability, synthetic data also enhances speed and scalability. Teams can generate exactly the data they need, when they need it, with the specific properties required for their use case. This accelerates development cycles and makes it easier to test systems under a wide range of scenarios, including edge cases that might never appear in real-world datasets.
Synthetic Data Generation Approaches
There are several approaches to generating synthetic data, each suited to different use cases. Below are some of the most common types:
- Fully Synthetic Data:
Fully synthetic data is entirely generated from models and does not rely on any real-world data. For example, a deep learning model like a Generative Adversarial Network (GAN) can be trained to generate images or text that resemble real-world examples. This type of synthetic data is valuable when there is a need for completely privacy-preserving data that does not contain any identifiable information. - Partially Synthetic Data:
In this case, real-world data is used as a starting point, but key components, typically sensitive or identifiable information, are replaced with synthetic values. This method balances privacy and utility, making it suitable for use cases where preserving the overall structure of the data is essential. For instance, an original healthcare dataset might have personal identifiers replaced with synthetic data while maintaining the statistical relationships between medical variables. - Hybrid Synthetic Data:
Hybrid synthetic data combines real-world data with synthetic elements to enhance the dataset. In this case, real data provides a foundation or framework, and synthetic data is introduced to fill in gaps, increase variety, or expand the dataset. This is often used to create large, diverse datasets where real-world data is limited or lacks variety (e.g., rare events in fraud detection or extreme weather scenarios in climate modeling).
How to Generate Synthetic Data
Procedural Generation:
Procedural generation relies on predefined rules, randomness, or mathematical models to create synthetic data. The generated data can range from simple numerical arrays to rich, lifelike synthetic profiles, depending on the level of complexity in the rules applied.
This method is well-suited for a range of strategic use cases:
- Rapid Prototyping and Early Development:
Synthetic datasets can be generated in minutes, enabling teams to begin building and testing systems before real data becomes available or approved.
- Safe Testing Environments with No Privacy Risk:
When dealing with non-sensitive domains, procedural methods eliminate the need for access controls, legal review, or compliance delays, making them ideal for internal QA or staging environments.
- Simulation of Rare Events and Edge Cases:
Unlike real datasets, which may lack diversity in certain scenarios, procedurally generated data can be engineered to include rare or extreme values, critical for stress testing and system hardening.
Two common approaches in procedural data generation include:
Basic Random Data Generation with NumPy
NumPy is a fundamental Python library for numerical computing, offering tools to create random datasets for testing and simulation. Developers can generate arrays of data that follow uniform, normal, or custom distributions, or even define constraints and relationships to simulate more realistic structures.
The following example uses NumPy to create a synthetic dataset with 1,000 records. Each record has a unique user ID, a purchase amount generated from an exponential distribution, and an activity status as a binary value.
import numpy as np
import pandas as pd
import uuid
def generate_synthetic_dataset(n_samples=1000):
# Generate synthetic data
user_ids = [str(uuid.uuid4()) for _ in range(n_samples)]
purchase_amount = np.random.exponential(scale=200, size=n_samples)
is_active = np.random.choice([0, 1], size=n_samples, p=[0.2, 0.8])
# Create DataFrame
df = pd.DataFrame({
'user_id': user_ids,
'purchase_amount': purchase_amount,
'is_active': is_active
})
return df
df = generate_synthetic_dataset(1000)
print(df.head())
Result:

Generating Realistic Data using Faker Library
The Faker library enables the creation of synthetic but highly realistic personal and business data, such as names, addresses and emails. It’s particularly useful for testing applications that require user-like data without compromising privacy.
The example below uses the Faker library to generate a synthetic user profile. Each profile includes fields such as a unique user ID, full name, username, email, address, phone number, dates related to the user’s activity, status, role, and a profile picture URL.
from faker import Faker
import random
import uuid
# Create a Faker instance
fake = Faker()
# Generate a fake user profile
def generate_fake_user():
user = {
"user_id": str(uuid.uuid4()),
"full_name": fake.name(),
"username": fake.user_name(),
"email": fake.email(),
"address": fake.address(),
"phone_number": fake.phone_number(),
"date_of_birth": fake.date_of_birth(minimum_age=18, maximum_age=90).isoformat(),
"date_joined": fake.date_between(start_date='-3y', end_date='today').isoformat(),
"last_login": fake.date_time_this_year().isoformat(),
"status": random.choice(["active", "inactive", "pending"]),
"role": random.choice(["user", "admin", "moderator", "viewer"]),
"profile_picture_url": fake.image_url(),
}
return user
fake_user = generate_fake_user()
for key, value in fake_user.items():
print(f"{key}: {value}")
Result:
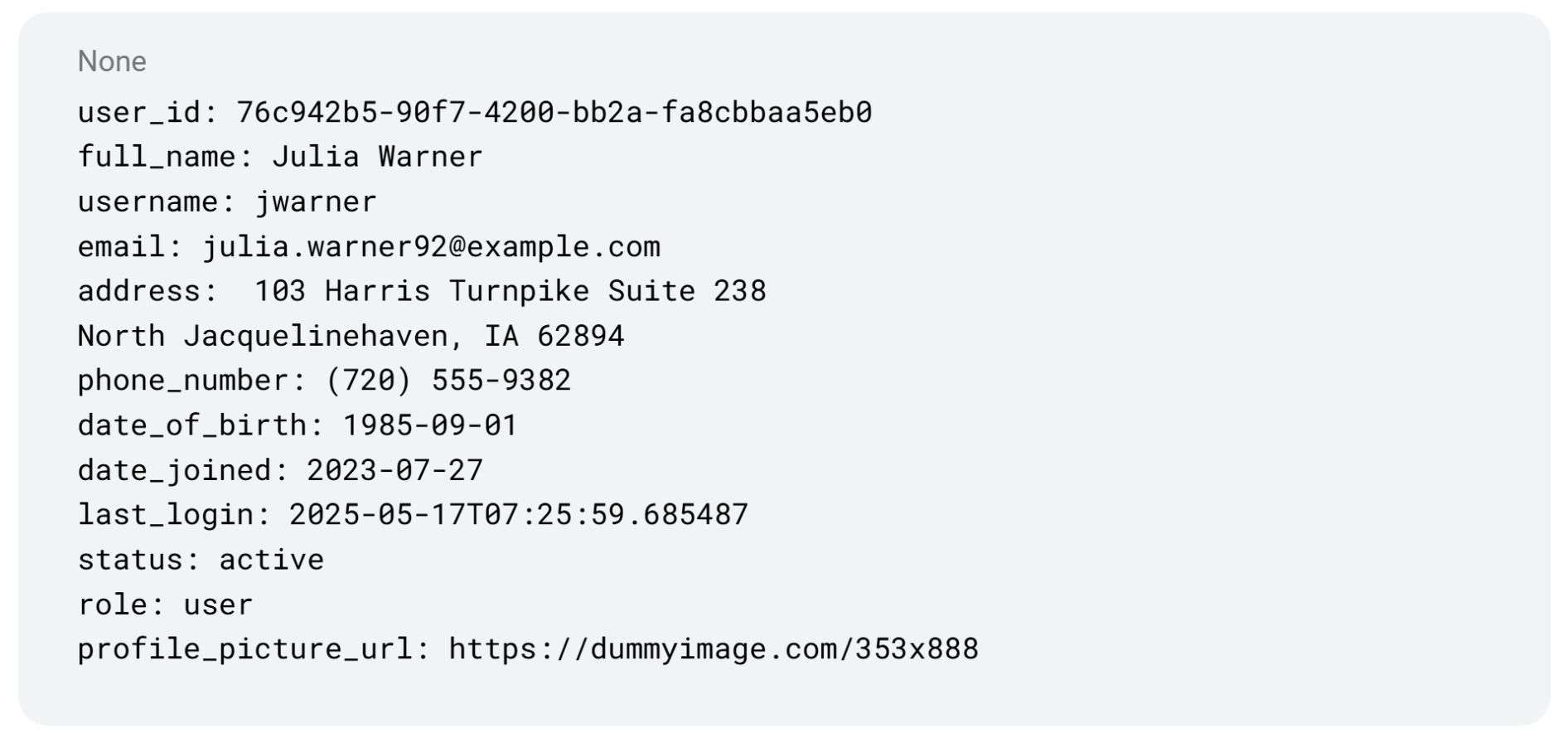
This type of synthetic profile data is ideal for interface testing, CRM simulations, and applications where realistic structure is more important than exact accuracy.
AI-Driven Synthetic Data Generation
While procedural generation relies on deterministic or rule-based systems to create synthetic data, AI-driven methods, particularly Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), represent a more advanced and flexible approach. These models go beyond templated or random generation by capturing complex relationships, contextual dependencies, and edge cases found in real-world scenarios. By learning the underlying data distributions, they can produce synthetic samples that are often indistinguishable from actual data.
This method is strategically valuable when an organization requires realism, compliance readiness, or machine learning acceleration:
- Accelerating Machine Learning with High-Fidelity Data
AI models can generate synthetic datasets that mirror the structure, distributions, and edge cases of production data, without the bottlenecks of data acquisition or labeling. It is particularly well-suited for fine-tuning large language models, testing computer vision systems, and simulating temporal sequences in forecasting applications.
- Reducing Risk in Regulated or Sensitive Data Environments
In industries like healthcare, finance, and legal tech, AI-generated data provides a privacy-preserving alternative to real data. It enables teams to prototype, test, and train models concurrently with legal reviews or data access approvals, reducing reliance on slow and expensive de-identification processes. Furthermore, it supports compliance with frameworks such as GDPR, HIPAA, and CCPA by leveraging techniques like differential privacy and generative detachment from original records.
- Simulating Realistic Behavior and Context-Aware Scenarios
Unlike procedural generation, which is limited by predefined rules, AI-driven synthetic data can emulate complex, human-like behavior and context-aware patterns. This makes it particularly effective for testing systems such as recommendation engines, voice assistants, conversational AI, and personalization features in realistic environments. It can generate adaptive synthetic users, sessions, or conversations that respond to dynamic inputs, ideal for stress testing and behavioral model training. Additionally, it supports continuous integration by producing fresh, in-distribution test cases on demand.
Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) are a class of machine learning models introduced by Ian Goodfellow et al. in 2014. They are designed for generative modeling, a type of unsupervised learning that involves automatically discovering and learning the patterns in input data in such a way that the model can generate new instances of data that are similar to the training set.
A GAN consists of two neural networks trained simultaneously in a competitive setting:
- Generator (G): Learns to produce data that mimics the training distribution. It starts from a random noise vector and attempts to generate realistic outputs.
- Discriminator (D): Learns to distinguish between real samples (from the dataset) and fake samples (from the generator).
The goal of the generator is to produce outputs that the discriminator cannot distinguish from real data, while the discriminator’s objective is to correctly classify real and generated samples. This adversarial training loop continues until the generator produces data that is nearly indistinguishable from the real data.
The training process typically involves the following steps:
- Noise Sampling: A latent vector z is sampled from a predefined distribution (e.g., normal or uniform).
- Data Generation: The generator transforms z into a synthetic data sample G(z).
- Discrimination: Both real samples and generated samples are fed to the discriminator, which outputs probabilities indicating authenticity.
- Loss Computation:
- The discriminator is trained to maximize the probability of correctly identifying real vs. fake samples.
- The generator is trained to minimize the discriminator’s ability to detect fake data.
- Backpropagation: Gradients are computed and both networks are updated accordingly.
This training process runs over many iterations (epochs), with both networks improving over time. However, to ensure the generator and discriminator learn effectively without instability or collapse, it’s important to carefully tune the model architecture, learning rates, and loss functions.
An example of GAN-Based Synthetic Data Generation Using Python
There are several Python libraries and frameworks available for building and training GANs. TensorFlow includes high-level APIs via Keras that make creating custom GAN models easier. The example below demonstrates how to build a simple GAN in Python to generate synthetic one-dimensional data points following a uniform distribution between 2 and 4. Both the generator and discriminator are small networks, which keeps the example straightforward and fast to run but limits their ability to capture complex data distributions. To ensure the generator’s outputs stay within the desired range, its final layer uses a tanh activation followed by rescaling from the typical [-1, 1] range to [2, 4]. This approach helps the model generate valid samples more reliably.
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
# Real data: Uniform distribution between 2 and 4
def sample_real(n=16):
return np.random.uniform(low=2.0, high=4.0, size=(n, 1)).astype(np.float32)
# Generator model
def build_generator():
return tf.keras.Sequential([
layers.Dense(8, activation='relu', input_shape=(1,)),
layers.Dense(1, activation='tanh'),
layers.Lambda(lambda x: (x + 1) * 1.0 + 2.0) # Rescale from [-1,1] to [2,4]
])
# Discriminator model
def build_discriminator():
return tf.keras.Sequential([
layers.Dense(8, activation='relu', input_shape=(1,)),
layers.Dense(1, activation='sigmoid') # Output: probability (real/fake)
])
# Build and compile models
generator = build_generator()
discriminator = build_discriminator()
discriminator.compile(optimizer='adam', loss='binary_crossentropy')
# Combine models into a GAN
discriminator.trainable = False
gan_input = layers.Input(shape=(1,))
gan_output = discriminator(generator(gan_input))
gan = tf.keras.Model(gan_input, gan_output)
gan.compile(optimizer='adam', loss='binary_crossentropy')
# Training loop
def train_gan(steps=500, batch_size=16):
for step in range(steps):
# Train discriminator
real_data = sample_real(batch_size)
noise = np.random.uniform(-1, 1, size=(batch_size, 1))
fake_data = generator.predict(noise, verbose=0)
x = np.vstack([real_data, fake_data])
y = np.vstack([np.ones((batch_size, 1)), np.zeros((batch_size, 1))])
discriminator.train_on_batch(x, y)
# Train generator
noise = np.random.uniform(-1, 1, size=(batch_size, 1))
misleading_labels = np.ones((batch_size, 1)) # Generator wants to trick discriminator
gan.train_on_batch(noise, misleading_labels)
# Train the GAN
train_gan()
# Generate and print 5 synthetic values
test_noise = np.random.uniform(-1, 1, size=(5, 1))
generated_values = generator.predict(test_noise, verbose=0)
print("\nGenerated synthetic values:")
for i, val in enumerate(generated_values, 1):
print(f"Sample {i}: {val[0]:.3f}")
Synthetic Tabular Data Generation Using CTGAN and Python
Generating synthetic tabular data is a valuable technique for creating realistic, privacy-preserving datasets that maintain the statistical relationships found in original data. This approach is especially useful when access to real data is limited due to privacy, security, or operational challenges. Additionally, it offers a cost-effective way to populate development and testing environments by avoiding duplication of complex ETL pipelines and reducing operational overhead.
The Synthetic Data Vault (SDV) library offers a range of tools for synthetic data generation, including models based on Generative Adversarial Networks (GANs). One such model is CTGAN (Conditional Tabular GAN), which is specifically designed to handle the unique challenges of tabular data. CTGAN can model mixed data types and capture complex dependencies between columns, making it well-suited for generating high-quality synthetic tables.
The following example illustrates generating synthetic e-commerce transaction records from a simple dataframe with a limited number of entries.
In real scenarios, the training data usually originates from an external file or data source. Additionally, metadata should either be inferred from the data or constructed dynamically to accurately represent the dataset’s structure and relationships.
import pandas as pd
from sdv.single_table import CTGANSynthesizer
from sdv.metadata import Metadata
transaction_data = pd.DataFrame({
'transaction_id': ['a1b2c3', 'd4e5f6', 'g7h8i9', 'j0k1l2', 'm3n4o5'],
'user_id': ['f47ac10b-58cc-4372-a567-0e02b2c3d479',
'9c858901-8a57-4791-81fe-4c455b099bc9',
'16fd2706-8baf-433b-82eb-8c7fada847da',
'6fa459ea-ee8a-3ca4-894e-db77e160355e',
'7c9e6679-7425-40de-944b-e07fc1f90ae7'],
'product_category': ['books', 'electronics', 'clothing', 'books', 'clothing'],
'purchase_amount': [23.5, 99.9, 45.0, 12.0, 55.5],
'purchase_date': ['2025-01-10', '2025-02-15', '2025-03-20', '2025-01-30', '2025-04-05'],
'payment_method': ['credit_card', 'paypal', 'credit_card', 'paypal', 'debit_card']
})
metadata = {
"tables": {
"transactions": {
"primary_key": "transaction_id",
"columns": {
"transaction_id": {
"sdtype": "id",
},
"user_id": {
"sdtype": "categorical"
},
"product_category": {
"sdtype": "categorical"
},
"purchase_amount": {
"sdtype": "numerical",
"computer_representation": "Float"
},
"purchase_date": {
"sdtype": "datetime",
"datetime_format": "%Y-%m-%d"
},
"payment_method": {
"sdtype": "categorical"
}
}
}
},
"relationships": [],
"METADATA_SPEC_VERSION": "V1"
}
# Creating a Synthesizer
synthesizer = CTGANSynthesizer(Metadata.load_from_dict(metadata))
synthesizer.fit(transaction_data)
# Generate synthetic data
synthetic_data = synthesizer.sample(num_rows=500)
print("\nSyntehtic data generated example:")
print(synthetic_data.head())
Result:

Variational Autoencoders (VAEs)
Variational Autoencoders (VAEs) are a type of generative model used to create synthetic data by learning patterns and structure from real data. Unlike traditional models that just compress and decompress data, VAEs are designed to understand the distribution of the data, allowing them to generate new, similar samples in a controlled and consistent way.
A VAE is built around two core components:
- An encoder, which takes real data and transforms it into a simplified internal representation.
- A decoder, which takes that internal representation and tries to reconstruct the original data or generate new, similar data.
What sets VAEs apart is that they don’t just memorize data. They learn a probabilistic model of how the data is structured, which allows them to create entirely new examples that follow the same patterns as the original dataset.
This makes VAEs particularly useful for generating synthetic data that’s not just random noise, but actually useful for training machine learning models, testing software, or enhancing data pipelines.
During training, a VAE learns how to compress data into a smaller form (called the latent space) and then rebuild it accurately. The model also learns how to keep this internal representation organized and smooth — which is important for generating new data that’s consistent and realistic.
Once trained, the model can generate new synthetic data by simply sampling from this learned space, making it a reliable tool for data augmentation, simulation, or experimentation.
An example of VAEs-Based Synthetic Data Generation Using Python
The following example shows how to use a Variational Autoencoder (VAE) to create synthetic data from a real-world table of information (the UCI Adult dataset). First, the data is prepared by converting categories into numbers and scaling values. The VAE learns to compress the data into a simpler form and then recreate it as closely as possible. Once trained, new synthetic data is generated by creating examples from this compressed form and converting them back to the original format. The synthetic data maintains the general patterns of the original and can be used for tasks like testing models or sharing data without revealing sensitive details.
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder, StandardScaler
import tensorflow as tf
from tensorflow.keras import layers, losses, Model
# Load UCI Adult dataset
data = fetch_openml(name='adult', version=2, as_frame=True)
df = data.frame.dropna() # drop rows with missing values
# Separate features and target (target not needed for synthetic generation)
X = df.drop(columns='class')
# Preprocess data: One-hot encode categorical, scale numeric
categorical_cols = X.select_dtypes(include=['category', 'object']).columns.tolist()
numerical_cols = X.select_dtypes(include=['int64', 'float64']).columns.tolist()
# One-hot encode categoricals
encoder = OneHotEncoder(sparse_output=False, handle_unknown='ignore')
X_cat = encoder.fit_transform(X[categorical_cols])
# Scale numerical features
scaler = StandardScaler()
X_num = scaler.fit_transform(X[numerical_cols])
# Combine processed features
X_processed = np.hstack([X_num, X_cat])
# Train/test split
X_train, X_test = train_test_split(X_processed, test_size=0.2, random_state=42)
# VAE architecture parameters
input_dim = X_train.shape[1]
latent_dim = 10
intermediate_dim = 64
# Encoder
inputs = layers.Input(shape=(input_dim,))
h = layers.Dense(intermediate_dim, activation='relu')(inputs)
z_mean = layers.Dense(latent_dim)(h)
z_log_var = layers.Dense(latent_dim)(h)
# Sampling layer
def sampling(args):
z_mean, z_log_var = args
epsilon = tf.random.normal(shape=(tf.shape(z_mean)[0], latent_dim))
return z_mean + tf.exp(0.5 * z_log_var) * epsilon
z = layers.Lambda(sampling)([z_mean, z_log_var])
# Decoder
decoder_h = layers.Dense(intermediate_dim, activation='relu')
decoder_mean = layers.Dense(input_dim, activation='sigmoid')
h_decoded = decoder_h(z)
x_decoded_mean = decoder_mean(h_decoded)
# VAE model
vae = Model(inputs, x_decoded_mean)
# Loss: Reconstruction + KL divergence
reconstruction_loss = losses.mse(inputs, x_decoded_mean) * input_dim
kl_loss = -0.5 * tf.reduce_sum(1 + z_log_var - tf.square(z_mean) - tf.exp(z_log_var), axis=1)
vae_loss = tf.reduce_mean(reconstruction_loss + kl_loss)
vae.add_loss(vae_loss)
vae.compile(optimizer='adam')
# Train VAE
vae.fit(X_train, epochs=30, batch_size=64, validation_data=(X_test, None))
# Generate synthetic samples
n_samples = 5
z_sample = np.random.normal(size=(n_samples, latent_dim))
x_decoded = decoder_mean(decoder_h(z_sample)).numpy()
# Postprocess synthetic data: inverse transform scaler and one-hot encoding
num_features = len(numerical_cols)
cat_features = len(categorical_cols)
# Inverse scale numeric
synthetic_num = scaler.inverse_transform(x_decoded[:, :num_features])
# For categorical, get argmax per category group
synthetic_cat_probs = x_decoded[:, num_features:]
cat_dims = [len(cat) for cat in encoder.categories_]
synthetic_cat = []
idx = 0
for dim in cat_dims:
cat_part = synthetic_cat_probs[:, idx:idx+dim]
synthetic_cat.append(np.argmax(cat_part, axis=1))
idx += dim
# Decode categorical indices to category labels
synthetic_cat_decoded = []
for i, cats in enumerate(encoder.categories_):
synthetic_cat_decoded.append(cats[synthetic_cat[i]])
# Combine numeric and categorical synthetic data into DataFrame
synthetic_df = pd.DataFrame(synthetic_num, columns=numerical_cols)
for i, col in enumerate(categorical_cols):
synthetic_df[col] = synthetic_cat_decoded[i]
print("Synthetic data sample:")
print(synthetic_df.head())
Result:

This example provides a clear and accessible introduction to using VAEs for synthetic tabular data generation. While it uses straightforward preprocessing and a simple model architecture, these choices may limit its ability to fully capture complex relationships or handle data imperfections often found in real-world datasets. The uniform loss function treats all features equally, which might affect reconstruction accuracy across different variable types.
For practical applications, enhancements such as advanced preprocessing (e.g., imputation, embeddings), deeper or more regularized models, customized loss functions, probabilistic sampling for categorical data, and privacy-preserving mechanisms like differential privacy can be incorporated. These improvements can increase the realism, usefulness, and compliance of synthetic data while building upon the solid foundation this example provides.
Choosing Between VAEs and GANs for Synthetic Data Generation
Variational Autoencoders and Generative Adversarial Networks present distinct trade-offs in model behavior, data quality, and implementation complexity.
VAEs are preferred when training stability, interpretability, and efficient resource use are priorities. They perform well on structured or sequential data and are suited for applications like anomaly detection, forecasting, and simulations where visual detail is less critical. Their simpler training process and lower computational requirements enable faster development and integration, reducing operational costs. Common use cases include financial fraud detection using synthetic tabular data, predictive maintenance in manufacturing, and privacy-preserving data generation in healthcare.
GANs, on the other hand, specialize in generating highly realistic synthetic data, making them particularly effective for image, video, and other media-rich applications. However, they require careful tuning, greater computational resources, and specialized expertise. Despite these challenges, they deliver strong value in domains such as autonomous driving, visual retail experiences, and cybersecurity, where detailed, high-fidelity data is essential for building robust, production-ready systems.
Ultimately, the choice depends on data type, desired output quality, infrastructure capabilities, and available budget. VAEs offer a practical and efficient solution when stability and speed are priorities, while GANs deliver higher realism when visual quality justifies the added complexity and resource investment.
Synthetic Data for fine tuning LLMs
Large language models (LLMs) such as GPT, PaLM, and LLaMA have shown remarkable capabilities across a wide range of natural language understanding and generation tasks. However, to perform well in specific domains or tasks, they often require fine-tuning. This process typically depends on large volumes of high-quality, labeled data which can be expensive, time-consuming, and highly domain-specific.
Synthetic data generation offers a promising alternative by providing abundant, cost-effective, and customizable training examples that reduce reliance on scarce or sensitive real-world data, enabling faster iteration and improved performance in specific domains or tasks.
One notable approach is presented in the paper Absolute Zero: Reinforced Self-play Reasoning with Zero Data. This research introduces a novel reinforcement learning paradigm where a model generates and solves its own reasoning tasks without relying on any external or pre-labeled data. The system, known as the Absolute Zero Reasoner (AZR), uses a code executor to validate and verify its generated tasks, effectively creating a self-supervised learning loop. Impressively, AZR achieves state-of-the-art results on coding and mathematical reasoning benchmarks, surpassing models trained on large, manually curated datasets.
This approach demonstrates that synthetic data generation, when coupled with self-supervised learning techniques, can significantly enhance the reasoning capabilities of LLMs without the need for extensive labeled datasets. For organizations, this translates into significantly reduced data acquisition and labeling overhead, faster AI development cycles, and accelerated time-to-market for AI-driven products, key advantages in today’s competitive landscape.
Challenges and Limitations
Synthetic data holds a lot of promise, but it’s not without its trade-offs. Like any tool, its value depends on how it’s used and understood. Two key challenges often surface: the potential to replicate biases present in the original data, and the difficulty of reliably measuring the quality of what’s been generated.
Risk of Bias Replication
Synthetic data is only as unbiased as the data it is trained on. Generative models learn statistical patterns from real datasets, and if those datasets contain historical or systemic biases, whether demographic, behavioral, or operational, these are likely to be mirrored or even amplified in the synthetic output. This can pose significant risks, particularly in sensitive domains like healthcare, finance, or recruitment, where decisions informed by data have high-stakes implications.
Moreover, the process of bias propagation may be non-obvious. Even when surface-level attributes appear balanced, deeper correlations can embed subtler forms of discrimination. Addressing this requires proactive auditing and debiasing strategies at both the data preprocessing and model training stages.
Difficulty in Evaluating Quality
Assessing the quality of synthetic data is complex, as it involves multiple, sometimes competing, dimensions. The most commonly used evaluation metrics fall into four categories:
- Fidelity: Measures how closely synthetic data resembles the real dataset in terms of distribution and structure. Common techniques include statistical similarity tests, dimensionality reduction visualizations (e.g., t-SNE, PCA), and classifier two-sample tests.
- Utility: Assesses whether models trained on synthetic data perform well on downstream tasks, ideally close to those trained on real data. This is typically validated by testing model performance (e.g., accuracy, error rates) on real hold-out datasets.
- Diversity: Captures how well the synthetic data spans the full range of possible values, especially rare cases. Lack of diversity can lead to brittle models, especially in domains with class imbalance or rare event prediction.
- Privacy: Ensures that synthetic data does not leak information about individual records from the original dataset. Common methods include membership inference tests, k-anonymity checks, and differential privacy guarantees.
Balancing these metrics is non-trivial. For instance, increasing fidelity may inadvertently reduce privacy, while maximizing diversity might impact utility. A strong evaluation strategy requires finding the right balance based on the specific use case and risk profile.
Conclusion
As data privacy regulations tighten and access to real-world data becomes increasingly constrained, synthetic data is emerging not just as a workaround, but as a strategic enabler for modern data-driven systems. By decoupling innovation from sensitive or scarce datasets, organizations can accelerate development, improve model generalization, and mitigate compliance risk across a wide spectrum of use cases.
From procedural methods and Faker-generated mocks to advanced generative techniques like GANs, VAEs, and CTGANs, the synthetic data ecosystem now offers mature tools capable of supporting complex machine learning pipelines, robust simulation environments, and fine-tuning workflows for large language models. However, realizing its full value requires a clear understanding of trade-offs, including fidelity vs. privacy, and diversity vs. utility.
For teams building scalable, privacy-aware AI systems, integrating synthetic data generation is rapidly becoming a foundational capability. It enables extensive, high-throughput experimentation without compromising sensitive data, thereby accelerating model development cycles. Additionally, it strengthens data infrastructure resilience by decoupling reliance on real-world data sources, which are often limited by regulatory constraints and availability. As a result, synthetic data generation is proving essential for organizations seeking to drive innovation responsibly while navigating complex privacy and compliance challenges.
Author:

Alessia Casagrande is an experienced Senior Data Engineer with a diverse background of working with companies ranging from startups to large enterprises. She is passionate about all things data, from building robust platforms to conducting in-depth analytics, and is always curious to explore the latest technologies in the field.