
This article is an introduction to the fundamentals of hexagonal architecture. We will firstly provide an interpretation of hexagonal architecture and its components, and then perform a thorough approximation using a simple use case as an example.
What is Hexagonal Design, and why should we use it?
If we want to go deeper into this subject, we first need to establish the context of our article, and we do so by exploring some of the concepts that surround Hexagonal Architecture.
Architecture
Why do we even speak about architecture and why is it so important to software engineering? Well, every time we write a piece of software/program, regardless of how small or big it is, we tend to assign a logical structure to it, so that its intention is comprehensible by others.
In its foundation, it’s about organizing things for a common goal. Of course, this is a very brief description, so let’s unfold what’s behind this sentence by quoting Uncle Bob’s words on architecture.
Uncle Bob states that Software Architecture must follow 5 main principles:
- Independence of Frameworks.
- Testable.
- Independence of UIs.
- Independence of Persistence.
- Independence of any external agency.
When it comes to architecture, every piece of software should be more or less consistent with such principles. There is also another variable that comes into play on this equation, and it’s the size of our application/solution: the smaller our domain is, the simpler our architecture should be, and consequently the other way around; that is common sense in action.
Design Patterns
Design patterns are a collection of techniques that are applied to specific scenarios in software development. There’s no obligation to implement them, but they are useful when modeling specific domains, especially rich ones. These patterns are typical of Object Oriented Design, but they could be applied to other programming grounds, such as functional programming. The concept was introduced and compiled by four authors that published a book named Design Patterns – Elements of Reusable Object-Oriented Software. These guys are well known in software circles as the ‘Gang of Four’ (G.O.F).
Rich and Poor Architectures
There are two types of architectural categories from a success standpoint: poor and rich architecture. The key difference is the architectural pattern. Poor architectures don’t follow any design patterns, and of course, rich designs subscribe to well-defined, standard patterns. It’s perfectly reasonable not to have a big design with small domains (no need for over-engineering), but as your application grows, the lack of a design pattern can cause a lot of headaches. Therefore, the key component of making the right architectural decision is to address the subject in the project’s early stages.
Both architectures will get the job done, but what makes an architecture successful is obtaining these application characteristics:
- Low Technical Debt
- High Maintainability.
- Easier Scalability.
We want our application to be very easy to maintain. If we are ambitious, we might eventually want it to scale to maximize revenue. Of course, our application can only be easy to maintain so long as we have designed a solution compliant with these characteristics from the very beginning. This will consequently lead to low technical debt which is often the elephant in the room for any software company. We want our software to be as profitable as possible, and this means keeping technical debt as low as possible. There are no shortcuts, only by devoting time and making the effort can you design a solid architecture from the beginning.
The Hexagonal Architecture
At this point, we have conveyed the fact that we need to apply good design to our software, ideally from the earlier stages, so let’s figure out the best approach to go with.
There are many names to the pattern we will discuss, but the one that best describes its essence is ‘Port and Adapters’. It’s all about defining ports and finding adapters that meet the desired behavior of such port definitions. Each side of our hexagon represents a port which will be engaged to any adapter built for it. We will visit this in depth later on.
It’s also worth mentioning something called ‘API driven design’ which goes hand in hand with hexagonal architecture and design.
API Driven Design
If we had to define an API, we’d say ‘Everything is an API’.
An API is what defines a specific logic in a piece of software. It’s compounded by a signature and a concrete implementation, which ultimately is what performs the operations to get things done. It may have dependencies on other APIs (the less the better). From an ontological standpoint, the most important component of an API is its signature. This is what declares the following information to the external world:
- What the API does via its name
- What it expects via its arguments(the less the better)
- What it returns via signature responses
Bearing this in mind, you can see that designing high-level solutions comes down to architecting software to define a series of business APIs that will conform to the core of our Domain. This series of APIs conform to the innermost layer of the onion architecture we are bound to build. This is the foundation of our building. Following this logic can make a real difference in our model that will set our application apart from the rest.
How our APIs communicate with each other and with the external world is extremely important. So, it is best to shape such relations by applying proper design patterns to our model on a case-by-case basis.
The Hexagon
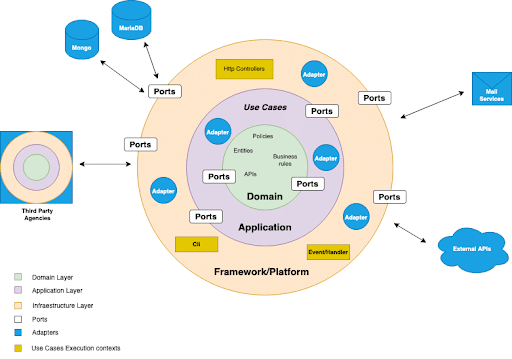
Here we use a circle-based diagram to point out that the hexagon is a rhetorical figure (there could be any number of sides to the hexagon) and to further express the idea that each side represents a port that accepts multiple adapters, while the duty of the system designers is to select the proper adapter for every port.
As you can see in the diagram, hexagonal architecture frames the application in multiple layers that represent the most important areas of concern to our system: Domain, Application and Infrastructure (mostly represented by Frameworks and Platforms). The manner in which layers communicate with each other is via ports (interfaces) and adapters (concrete implementations). Inner layers express the intention to communicate with external layers on their ports by defining the signatures others need to comply with in order to get in touch with them.
Domain Layer
This is the central layer in our system. Everything is devoted to the domain layer because it resides at the core of our application. Here, we find the business logic of our domain, what makes our application different from others, and what makes it valuable. It contains the business rules, policies, constraints, domain events, and services (repositories, factories, and services) related to our domain.
It also defines the policies for the use cases of our application. This is really important because we start shaping our application and how it interacts with the outside world (surrounding layers). It’s important to note that the domain layer doesn’t depend on any other layer. This is the highest level where policies live in our system. We will see later on how this happens through the use of interfaces.
Application Layer
In this layer, we define the ports to communicate with the infrastructure of our system. This layer bootstraps our real application, which actually lives in the domain layer.
We interface our use cases to the next upper layer, so every transformation, from low-level agencies to higher policies, which is what our domain understands, takes place here. I.e. framework machinery (Controllers, Event Handlers, external APIs, etc.)
The domain layer defines those use case signatures, and the application layer orchestrates the machinery that enables it to be consumed by the infrastructure layer. This includes transforming and processing requests, passing requests through to domain handlers that perform the business logic, and processing responses (if needed) to return to the outer layer in a language/format it understands.
In other words, we decouple our core application from the current framework or platform that we are developing.
Infrastructure Layer
Outside the application layer resides the framework, the UX, third party libraries, SDKs, and all other layers that support our application. However, these are not part of the core application. According to hexagonal architecture, they should not live in the foundations from where we disseminate our application.
The infrastructure layer depends upon application services and domain layers, and this is where hexagonal architecture shines the most. By applying Inversion of Control via Interfaces, we can make this layer a servant of our domain, and not the other way around. Our application knows nothing about what it relies upon. This layer also contains the configurations to our application, and it’s where we can connect our services to third party agencies via Dependency Injection Containers.
Interfaces, Adapters and Inversion of Control
The cornerstone of hexagonal architecture is the use of Interfaces. Traditionally, when we needed to use external services (located in the infrastructure layer) we’d add them in the signature of our API and use them in our custom logic in the same way we defined our services.
That approach is good, but it has one downside, and that is coupling. We want our applications to be:
- Easy to change
- Tested in isolation
- Rapidly scaling
However, coupling our logic to specific agencies is a big impediment to those goals. Let’s see this in action with an example.
A Use Case for Hexagonal Design:
Our use case is an SMS notification system that we need to include in our application. We want to use a third party notification system in order to accomplish our business goals and we will compare traditional vs hexagonal design approaches.
Traditional Approach:

This approach is valid, and it works just fine, but there are some considerations to be taken into account. Whoever uses this module needs to inject an instance of AwesomeSmsNotifier that may or may not be an abstraction. An abstraction is an interface defined by a third party and not by our application. This is not in our best interests because if some better/richer/more featured notifying system comes out, we might not only need to replace the signature in our classes but also the injections all other consumer classes perform on their side. If we are using a DI container ( ideal in the case of abstraction), it is only a matter of changing recipes in DIC settings. Otherwise, cumbersome work awaits us.
So, the problem here is that this approach leaves no room for simple changes to our application, and it also imposes a problem when trying to test this service in isolation because we might need to instantiate that third party with all that it entails.
Let’s Use Adapters
Adapter patterns provide mechanisms to wrap the functionality of one API and make it available to a third module that understands it because there is a high-level policy that allows for communication with low-level agencies. In this case, the consumer class and the provider of the functionality API are these low-level agencies.
In our example, if we need to replace the feature provider, then we just need to create a new adapter that implements our high-level policy (preferably defined in the application layer), wrap the call to it, and inject it via DIC to our consumer API. It’s that simple. Let’s flesh it out in code, and use PHP for our example.
Hexagonal Approach:
Notifier Interface: This is the port on the hexagon side (boundary):

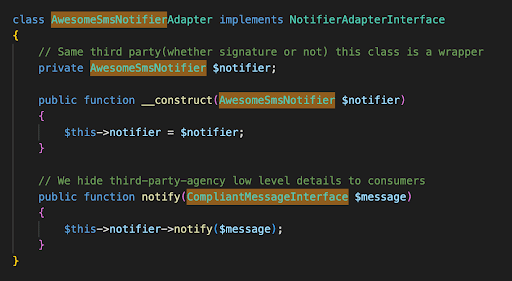
Notifier Adapter: This is the wrapper that hides low level details regarding communications with third party agencies from consumers:
Consumer Class New Implementation: this class won’t ever be changed and remains unchanged regardless of which service providers we’re using.
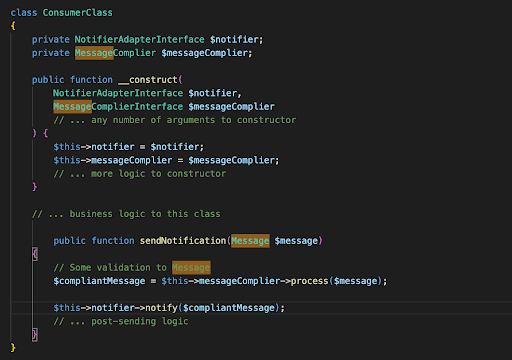
To put it plainly, what we do is:
- We create a Port(NotifierAdapterInterface) that defines the external feature(AwesomeSmsNotifier) in which we need to consume/use from our API.
- Write an adapter(AwesomeSmsNotifierAdapter) that connects to our port and wraps interactions within that feature.
- Any client class(ConsumerClass) using external service, requires our Port and we inject our Adapter(via DIC or whatever the mechanism).
By doing so, we enable more:
- Scalability: We make sure our APIs remain untouched by creating a wrapper to new third party APIs and changing recipes in DI containers. From this moment on, using one third party service or the other comes down to tweaking DIC settings.
- Re-usability: We’re also in the position of being able to use any of them on different parts of our application, even different services for similar consumers (real life often takes you to such Use Cases).
- Maintainability: If a problem arises with that very service (the service our adapter wraps), we just need to focus on our AwesomeSmsNotifierAdapter class that holds the low level details of this agency.
- Test-ability: We want to test our machinery without depending on external agencies. Because they are well proven services, we can mock them by creating test adapters that implement our high level ports and easily test them in isolation.
Inversion of Control
The phenomena going on here is actually the Inversion of Control principle defended by S.O.L.I.D adopters. The traditional approach dictates that our ConsumerClass includes AwesomeSmsNotifier as a dependency, and this creates a large dependency on that library. So, third party agencies have control over our domain because any changes/updates/upgrades in their libraries would produce the necessity for our domain to change as a result.
A Shift in Paradigm
Inversion of Control is basically a change of direction in that relationship, as our domain will no longer depend on third party modules, but instead upon a higher abstraction that connects our domain to those agencies (Infrastructure and the outside world). By doing so, it remains untouched by any external actors. Changes in outer layers modules will be handled by those abstractions that are already under our control.
It’s worth mentioning that this can be done within the relationship of any layer of our architectural landscape. The same applies to the application layer, and to the infrastructure (including the external world). Of course, the latter does this at its creator’s command.
Stability Rule
The stability rule states that dependencies point to stable components. Stable components are components that are as independent as possible. The more independent, the more stable, because it has no (or little) external components to depend on. Therefore, it has no (or little) reason to change.
Secondly, another measurement of stability is the volatility of components in our architecture. In comparison to the infrastructure it’s more likely that our domain will now change. External factors act in our favor in this regard (libraries update, framework upgrades, new mobile app, new frontend framework etc). Due to these factors, the domain layer is considered the most stable ground in our system.
Dependencies Pointing Inward
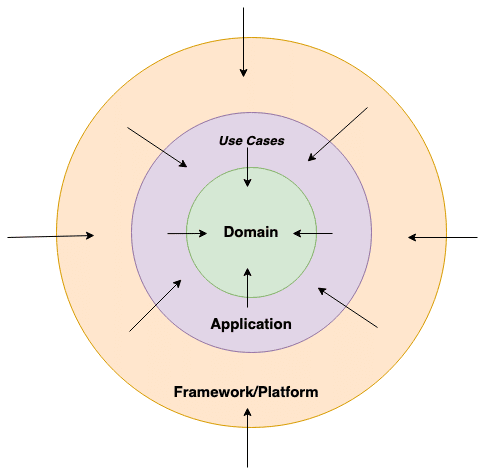
Dependencies pointing inward to the domain layer.
That is why all dependencies point inward in our onion model. The practical implementation of this is through the extensive use of interfaces, and enforcing the subsequent inversion of the control principle in our example.
As a practical tip, if you are digging into any system’s code base and you see lots of references in the domain layer (or its counterpart) to either frameworks, libraries, or SDKs, it could signal a violation of principles and patterns of hexagonal Design.
Final Thoughts on Hexagonal Design and Architecture
As a bottom-line statement to our article, we are not emitting judgment on any approach that is different from hexagonal or simply designed solutions. We do not believe that there are good or bad designs to software building. It all depends on the problem at hand that we are modeling for. We just want to provide an interpretation of hexagonal architecture by establishing a framework of analysis on why it’s important to consider the domain as the center of our system, especially when big/rich domains, and accompanying components are built from the inside to the outside. Finally, to paraphrase uncle Bob, “Everything but our domain is just a detail”.
If you have questions regarding the article, or require additional information on the topic, or want to connect with one of our software experts, please reach out!
—
Author:
