This article is the second article in a 2-part series on IIoT systems and IIoT implementation to leverage real-life insights. Feel free to read ‘Overview of an IIoT Solution: from data harvesting to ingestion‘ for more information.
Once data has been gathered within the plant floor and ingested by the system, what do you do with that massive amount of information? How can you make sense of all that raw data? In this article, we will cover different approaches for IIoT implementation on the back-end, how to deal with the gathered data, and finally, how users can interact with the system.
IIoT Implementation on the Back-end

Having said that, we will describe two possible scenarios and how we can tackle IIoT implementation on the back-end: simple business cases and complex business cases. This will provide an overview of the possible approaches and a practical example.
Simple Solutions
When talking about simple solutions, we are talking about solutions where we don’t want to differentiate between types of IoT events when processing them. Essentially, solutions where there is a homogeneous IoT message processing without priorities.
Let’s imagine a system where the business case we want to implement is the quality tracking of a manufacturing process. The system should gather certain information from the plant floor, ingest it, process it, and finally, offer part of that information to the final users. This system is something we can implement with, for instance, a simple microservices solution where each microservice has its bounded context inside the business case, and some of them are subscribed to the IoT events generated within the plant floor. Each microservice would have its own database acting as the IoT data storage.
The diagram for this solution would be this one:
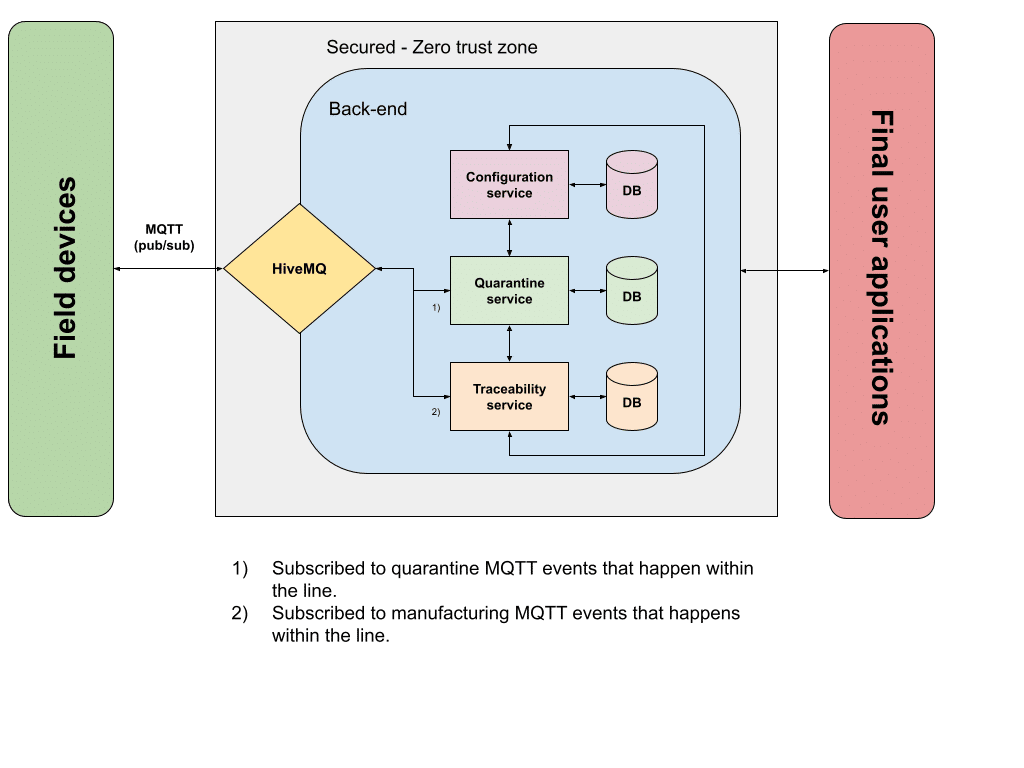
This hypothetical system generates two different types of events: traceability and quarantine events. These events, in practice, are MQTT messages published to our IoT Broker (HiveMQ in this example, although this is valid for any other pub/sub-IoT broker) when the manufactured parts are processed within the production line.
Traceability events are generated when every single manufactured part arrives at one of the multiple stations within the line, and there an operation is made against that part. For example, a machining operation. The IoT device attached to this operation retrieves all the data associated with it (date and time, machining parameters…), and then publishes this IoT event. On the back-end side, while taking advantage of the IoT broker pub/sub infrastructure, the traceability microservice retrieves this event as it is subscribed to the topic. Once the event is handled by the microservice, business logic is applied: storing the information for hypothetical reporting features, checking that all manufacturing parameters are good, etc…
Quarantine events are generated by a subset of operations inside the line. Let’s imagine that a component that should be attached to the main part being manufactured is provided by a third-party company. They send these components in big boxes, where all of them belong to a lot. In order to keep track of these components, there is a specific station loading these components into the line and checking that the components match the specifications. If for some reason, one of the components has a defect, the business rule is to quarantine all the components that belong to the same lot and the parts where they were attached, if any. When a defectuous component is detected, an IoT event is sent to the back-end to trigger the specified process to implement this business rule. In the same way as the traceability event, it all starts with the MQTT event published by this component-loading station and handled by the quarantine microservice. This microservice will be working in combination with other microservices to satisfy the business rule we described above.
The approach described above with traceability and quarantine events can be extended as much as you want. The key idea behind this is that field devices are publishing MQTT events that will be consumed by the back-end subscriber(s), using our IoT broker infrastructure. These back-end consumers can be architected as any other system. From a monolith approach to a combination of microservices aimed to implement the business rules required to satisfy the use cases of our system.
Advanced solutions
On the other hand, we have advanced IIoT solutions. These kinds of solutions handle more complexity in terms of the variety of events and the priority of these events. For instance, within all the different events, some of them are mission-critical (may involve process’ safety) and some of them are just data that should be aggregated at the end of the day to generate some reporting. How can we deal with these scenarios? To answer this question, let’s introduce another hypothetical industrial process we should handle with our IIoT system.
Let’s imagine the industrial process for a steel industry company that makes bars of steel used by other manufacturers. This company wants to monitor a wide range of parts of the process, including the oven temperature, the quality tracking for the bars ( from the oven to their shipping), and the temperature of the different areas of the factory to analyze the labor conditions and make decisions in the mid-long term to improve the conditions of the workplace.
As we can see, in terms of business rules, we are talking about different elements. For instance, the oven temperature should have real-time monitoring/data gathering since there must be a hard threshold where the oven will be quickly cooled if it exceeds a certain temperature to ensure the integrity of its components: this involves a mission-critical event as it affects the process’ safety. This is a significantly different necessity compared to data aggregation related within workplace reporting, where we don’t need real-time monitoring at all.
To achieve this data categorization, and decide how we want to process every single event, we can take advantage of the concept of data paths.
Data paths
The idea behind the data paths approach is really simple: analyze in real-time, the events that are ingested to categorize them and decide which part of the IIoT system should handle them. This idea goes hand in hand with the concept of stream processing.
Let’s take a look at a diagram where all these ideas are put together.
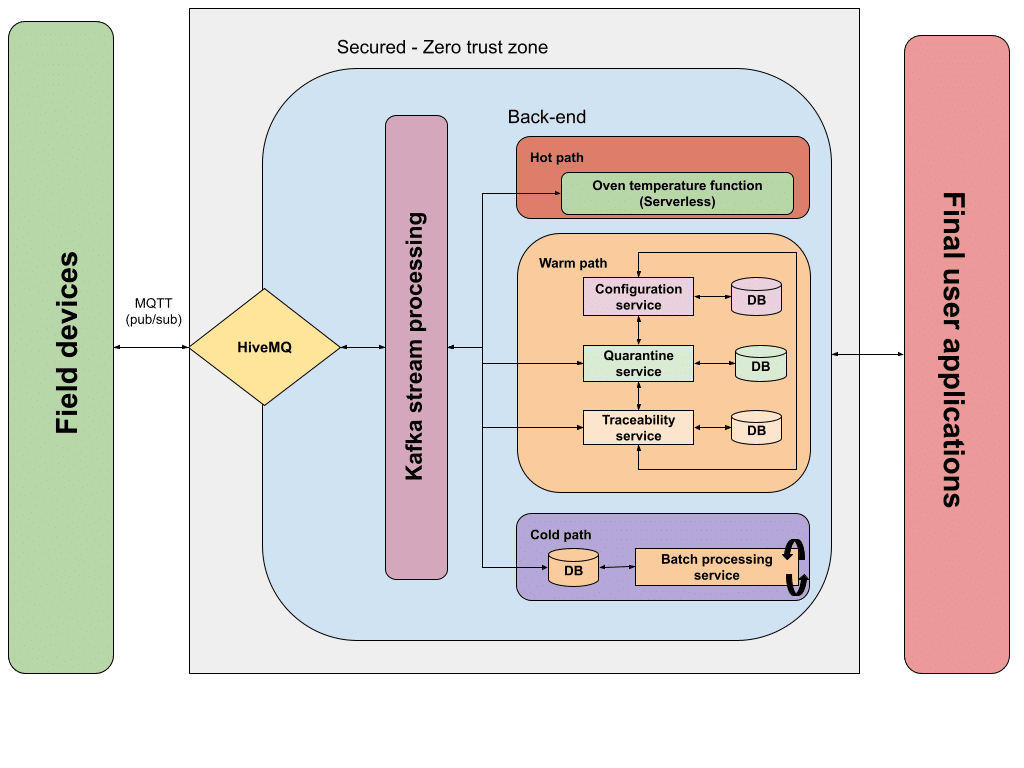
When a new event is ingested (HiveMQ in this example, but you can think of any other IoT broker), it is processed by the stream processing engine (diagram shows Apache Kafka, but any other stream processor can be used here). Stream processing engines, based on the predefined rules, are able to categorize the event that just arrived, sending it to one of the data paths for processing: hot, warm or cold data paths. This categorization can be understood as an ETL process.
Hot
Hot data path is intended to represent the part of the system that should take care of the event data that is processed in near-real-time. In this path, processing should occur with really low latency and can be understood as the data path with the highest level of priority.
In our hypothetical system, this path would handle the MQTT events sent by the oven reporting the actual temperature. This event should be handled in real-time to make critical decisions (in our hypothetical case the system can start the cooling process when the hard threshold is reached). In our diagram, this decision is made by a serverless function (Azure functions for instance) where the appropriate business rules are applied.
Warm
Warm data path is in charge of dealing with the events that should be processed as soon as possible but can accommodate longer delays. This path is ideal for normal event handling and can be considered the data path with an average level of priority.
This, translated to our hypothetical system, fits with the processing of the quality tracking of the manufactured steel bars. The different stations/operations within the line will be publishing MQTT events tracking every single unit, where they are, and which actions are done against them. These events will be ingested and then redirected to the warm data path by the stream processor. This data path, similar to the system we described in the “simple solutions” section, is implemented by a microservice sub-system.
Cold
Cold data path represents the lowest priority in terms of message processing. Usually, this path is related to batch processing activities that manage large volumes of data, and get triggered periodically (hourly or daily, for instance). In this data path, the system can accommodate large delays as the information and processes being executed here are not a top priority.
In our system, this is represented by the batch processing service and its data store. The workplace temperatures are gathered by the appropriate sensors and published as MQTT events. Then, the stream processing engine categorizes these events and sends them to the database that stores this information for batch processing, which will happen periodically. This part of the system can be implemented by a combination of a database and a separated service, or by using cloud services like Azure Batch.
Back to The Plant Floor

We have been describing a few options on how the gathered data can be processed by our back-end, but there is a critical question that is still pending to be addressed: How can we interact with the plant floor from our back-end? This question is not trivial, as many of the IIoT systems cannot be designed as data gathering systems, because we want to react to the events that are happening within the plant floor. Let’s explore our available options.
Pub/Sub
If the IoT broker being used supports the publish/subscribe pattern, it can be used to implement duplex communication between IoT devices and the IoT back-end.
IoT devices can publish messages to a certain topic, which are usually capable of subscribing to topics as well. By taking advantage of this scenario, and organizing the topics carefully, IoT devices can exchange information using them. Let’s see a practical example:
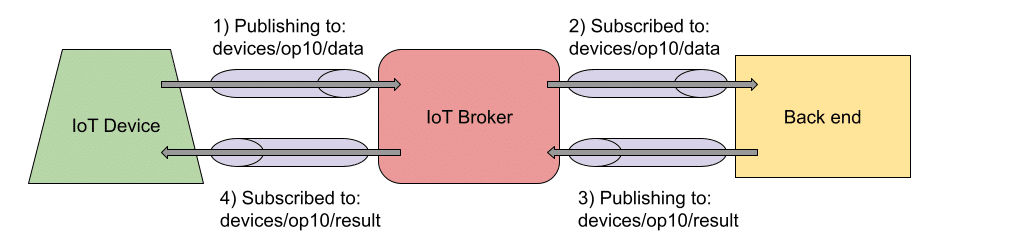
In this example, we have a hypothetical IoT device publishing the information that is being gathered into a particular topic: “devices/op10/data”. This topic name is not a random name as it includes the nature of the publisher “a device”, the identifier of the publisher “op10” and what the publisher is trying to achieve with this topic “publishing data”.
The subscribed components within the back-end (i.e. Traceability service) will receive the IoT event and process it accordingly. Let’s imagine that after the event processing, the back-end determines that the IoT device should perform an additional action. This can be achieved by the back-end component publishing another IoT event into a well-known topic intended to receive the responses. The topic would be “devices/op10/result”. Again, the name of the response topic is not a casual one, and it has the nature of the target “a device”, the identifier of the target “op10”, and the goal of this topic “receive result events”. The IoT device subscribes to the response topic and uses the information received to determine the appropriate action.
As a recommendation, it is a good idea to provide a correlation identifier in the published data and published response to allow the IoT device to associate a published message with its response. This allows you to avoid issues when multiple events arrive at the resulting topic.
If for some reason, the IoT device that we want to act after certain messages, is not able to subscribe to a topic in order to receive the responses for its messages, consider treating this device as a not-so-smart device, and take advantage of one of the possible solutions we described in our first article: explore hardware alternatives or configure this device behind an IoT gateway.
Built-in Features
Some of the IoT brokers provide built-in options for sending messages from the back-end to the IoT devices at scale. Here we will be reviewing the options that main cloud providers offer to us to help with the integration of IoT and cloud computing platforms.
For instance, in the case of Azure IoT Hub, the platform allows three different types of cloud-to-device communication for both MQTT and AMQP protocols:
- Direct communication. This approach is intended to provide a way to invoke direct methods on devices from the cloud. This can be used to implement the request-response pattern and allow us to send operation results to our devices.
- Device twins approach. This approach is the perfect way to control a device’s metadata, its configuration, or long-term conditions defined within the device itself.
- Cloud to device notifications. This approach basically implements a one-way communication, can be useful to notify events within the system, and can let the device to act accordingly if needed.
On another hand, Amazon IoT Core provides a single built-in option to implement this cloud-to-device communication:
- AWS IoT Device Shadow Service. This service is intended to provide a solid approach to exchanging information with devices beyond the raw MQTT publish/subscribe option we described above.
In contrast, compared to other cloud providers, Google IoT Core options are built around the publish/subscribe approach we have described before. See Google commands.
If for some reason, the IoT device you want to communicate with is not able to deal with these built-in features, you can always consider putting it behind an IoT Gateway, which can deal with the implementation details of these communication types.
Final User Applications
So, how will IIoT implementation benefit the end-users?
IIoT systems provide transparency for the industrial processes, and cover the gap between the physical and digital world. These systems enable users to make informed decisions based on data, and allow us to extract all the necessary information and use it to monitor, act, discover, and optimize weak points in the industrial process.
In this context, one of the ultimate goals of any IIoT system is to provide information to the end-users, and perhaps allow them to interact with the system via a web or mobile interface. These are some general considerations for these types of applications.
When dealing with applications that allow users to interact with the system, take advantage of architectural patterns like API Gateway or Backends for Frontends. This dedicated interface for user interaction will provide an entry point for the system, different from the IoT Broker, which should be solely focused on IoT event ingestion.
On another hand, reporting is always a component of any system. When possible, take advantage of data aggregation systems (see Splunk, Times Series Insights…) that can be plugged into your system, and can be used to generate the reports. If these systems are not an option, try to handle reporting as an additional layer of your system (reporting layer), which is subscribed to the needed events used to generate the reports without affecting the throughput of the ingestion/processing of the IoT events. This reporting layer would have its own persistence optimized for reporting, and possessing the data is the only requirement needed to generate the expected reports.
Finally, if other systems need to integrate with the IIoT system, a good recommendation would be to provide an integration layer (via API Gateway for instance) that abstracts the access to the back-end in charge of the event processing. This allows us to achieve the same isolation mentioned above to avoid impacting processing throughput.
Conclusion
We hope you enjoyed the second part of this IIoT implementation overview. We would like to finish by highlighting a few key takeaways.
First of all, don’t over-engineer your back-end. Analyze your solution to determine whether it can fit within the definition of a simple solution before starting to deal with stream processing engines and data paths just because they seem to be cool.
Secondly, if your system needs to communicate back to the plant floor, evaluate the ways that your IoT broker allows you to send messages to the IoT devices. This is a critical part, as performance and ease of implementation could tip the balance between IoT brokers.
Finally, avoid consuming the data generated by the system straight away after its processing, and consider using an integration layer for third-party integrations, if any. Alternatively, you can use a reporting layer or data aggregator systems to properly separate the concerns of your IoT system and maximize the processing capabilities of your back-end.
We hope considering these key aspects will help you follow the safe path to successful IIoT implementation.
Author:

—
If you need help developing IoT/IIoT solution or any other software product, Zartis developers can help!
With our bespoke team augmentation services, you can recruit world-class engineers and build high-quality software quickly, cost-effectively, and with minimal admin — all the while retaining complete control over the entire process.
Tell us about your project, or find out how the dedicated team model can level up your business. Drop us a line, we’ll be in touch shortly.