
Keith Redmond, VP of SaaS Engineering at Fenergo, shares his insights on how to utilize Event Sourcing with CQRS in your application development.
This article was presented as a webinar as part of the ‘Talking .NET’ conference, you can see the full webinar here.
What is Event Sourcing?
Event Sourcing is an application design pattern that focuses on tracking operations as a sequence of events which are then aggregated to produce system state.
You can not only query these events, but also use the event log to reconstruct past states, and to automatically adjust the state to cope with retroactive changes.
First and foremost, it’s about how to design your application to focus on tracking not just what your data looks like, but why your data looks that way. What are the operations that created the data that you’re storing and what is the sequence of events that produced your system state?
What is CQRS?
Command Query Responsibility Segregation (CQRS) is an architectural pattern that splits applications that operate on/create data apart from those which read data.
It is important not to confuse CQRS with concepts such as Service-Oriented Architecture and microservices, it’s not really about the size of what we’re trying to do, it’s not about the size of the applications or their granularity, it’s really about the operations that they perform. And Event Sourcing isn’t trying to be a silver bullet. It’s not trying to replace every other solution, but there are ways in which it can be a good choice for your business.
Centralized State Database
To begin a discussion about a change towards Event Sourcing and CQRS, it’s important to understand the challenges with the more traditional or common approaches. One of the best examples for that would be the Centralized State Databases, and how operations in your system can change the state of our database.
So to take a pretty simple example – in the graph below we have a state database and at the top, there are four business operations that can change the state of that data:
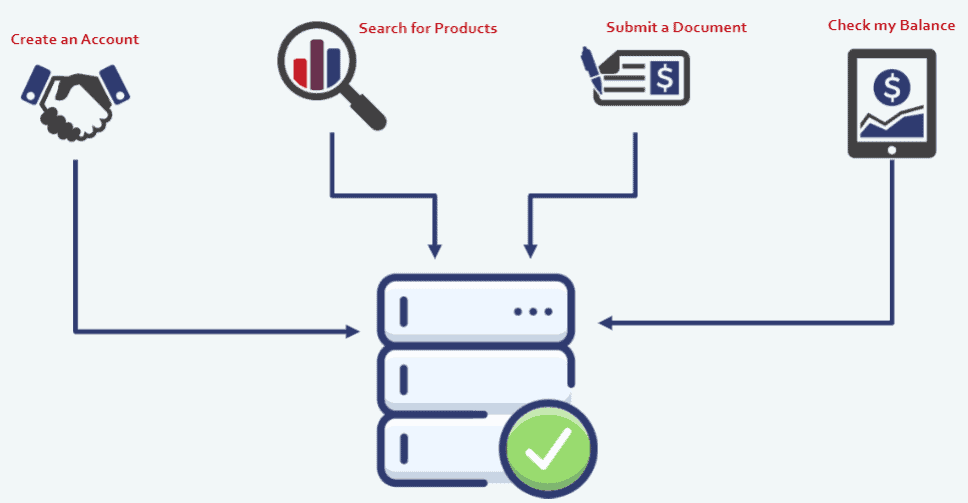
You could create an account which will produce a record and an account table; you can search for products in the state database and you can see the existing products; you can submit a document and it will be stored in the document storage and some metadata will be put into the state database; and you can also check your balance, so you can query the database to return specific information about your account.
Pros and Cons of using centralized databases:
Let’s explore some of the positives and negatives of a database like this.
The positives are that the database controls my transactions, so I get atomic transactions built in. I don’t have to duplicate a lot of data in a centralized state database, I can create first/second/third normal form objects in the database. The database can manage my security and give me access to backups and portability. And it makes the tech stack quite simple and easy to understand for people joining the team or people, trying to explain the architecture.
PROs |
CONs |
| Atomic transactions | Loss of Data |
| Less duplicated data | Performance is shared |
| Security offered by the database | I/O Contention and bandwidth bottlenecks |
| Easier backup and portability | Technology needs to accommodate many uses |
| Straightforward tech stack | Large blast radius |
There are also some challenges that it brings. The first one is that it loses data (we will touch on that later on). Performance is shared, so everyone who is reading data is competing with the people, who are writing data to the database for performance. That’s similar to I/O Contention – so all of the pipes into the database and out of the database are competing for bandwidth. If we pick one database technology, it means we need to solve many diverse challenges with it and a centralized state database produces a large blast radius – if that central database goes down, we have an issue, because a large percent of the application will be nonfunctional.
One of the most important things to touch upon in this table is the loss of data, which is also one of the main reasons why Event Sourcing can prove to be a better solution. In a centralized database you may not be able to track changes to objects or the reasons for those changes. To give an example, we can use the illustration below where a bank account holder could arrive at the account balance of 50000 in several different ways.
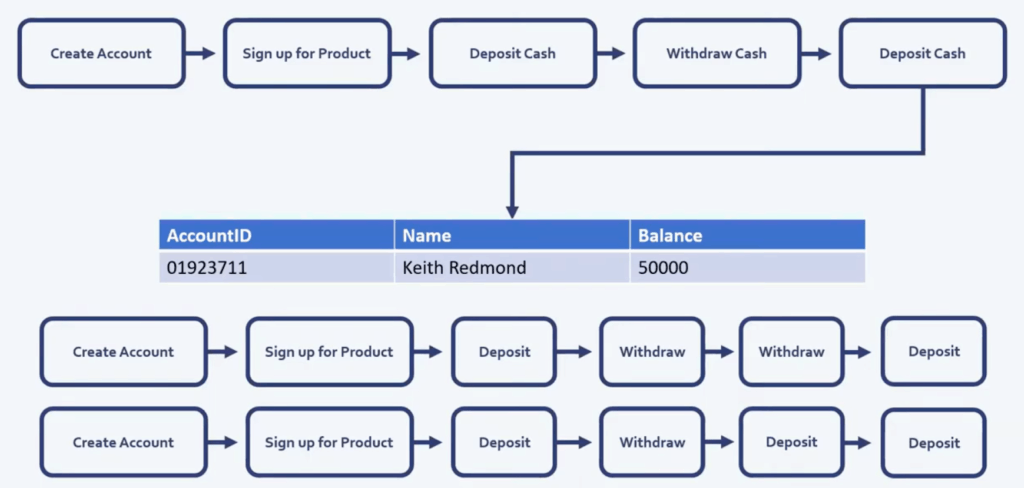
In a centralized database, we would not automatically be able to tell how the specific user ended up with 50,000 in their account. There are, of course, common ways to try to deal with this such as introducing an audit table and the flow at the top becomes the state record. See below.
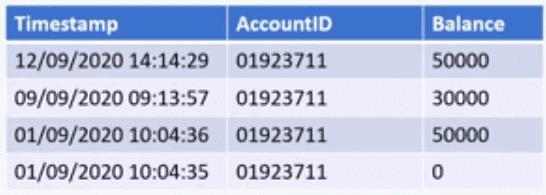
However, this still would not tell us why the state of the record changed, and so it becomes extremely difficult to rebuild your state. If you use an audit trail like this, you don’t know why 50K became 30K or why that 30K then became 50K. This can make it quite difficult to create a generic solution to produce these audit tables across different domains and you end up writing a lot of business logic.
Ultimately, what happens is, you end up with an audit table that covers some of your losses. Then, you will need to introduce a reporting layer to report on the central database, and audit users who want to order from that central database. This means, while you’ve solved some of your data loss, you have probably increased your performance challenge, and potentially put more I/O on the database.
This is where Event Sourcing becomes very useful. In event sourcing, the operations themselves are what you would store and you store them in the sequence that they happen, so that you can aggregate them together to produce your state.
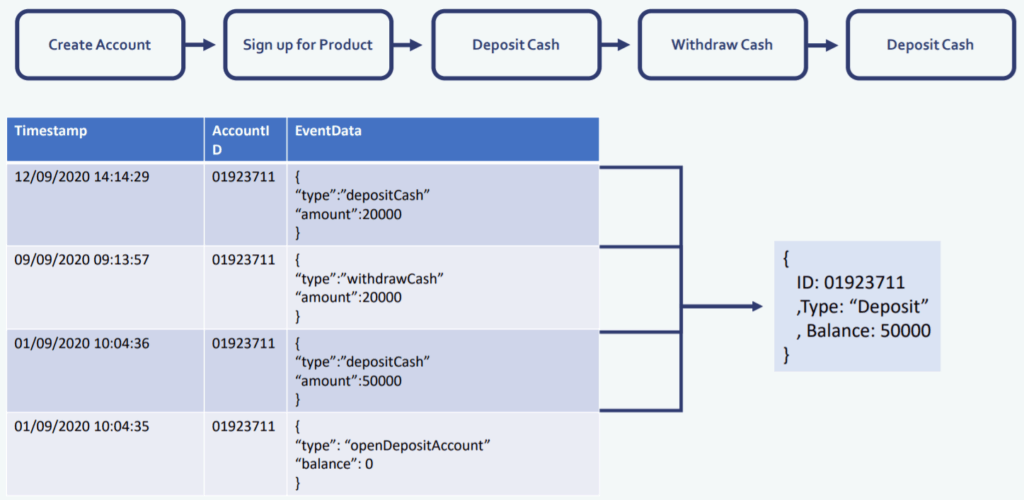
Let’s take a look at our example from an event sourcing point of view. What’s on the screen is the same flow as we had before in the centralized database design, so we arrive at the outcome of 50,000 as a balance again, but now we have all the context from business operations that got us to that point.
Utilizing event sourcing in this manner definitely will help you prevent data loss, and reliability however, you will probably still have challenges with I/O, performance, backup or upgrade. So, what do you need to do to actually deal with those challenges?
Event sourcing naturally comes with the idea of projection:
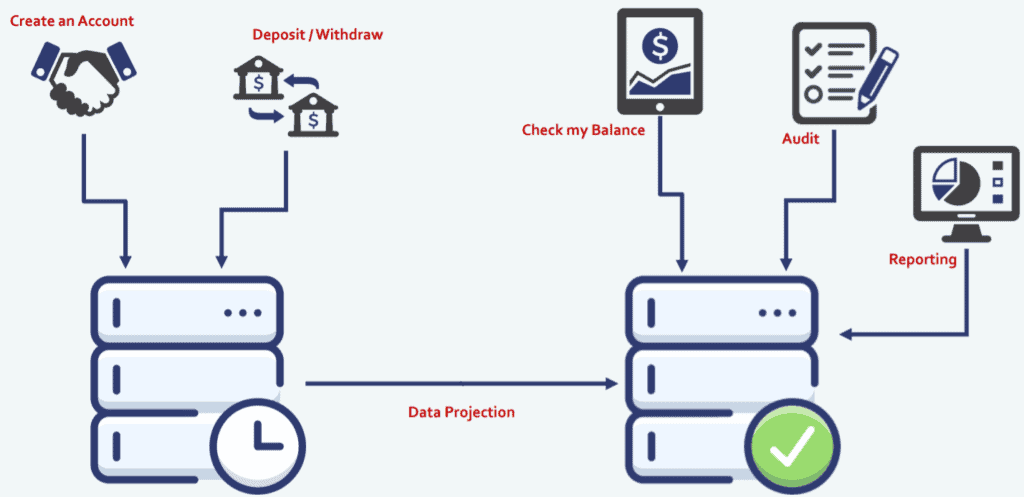
If you look at the diagram above, when we create an account, or when we deposit or withdraw, we store those things as business operations in our event source database. However, when we want to actually use that data to query current state, or historical state, or maybe audit, then we may want to read that from another database. So we introduce the database on the right, which is essentially a state database. In the center, we have an arrow – data projection – representing where we iterate over our historical business operations and we create the state as we need it for queries.
In this structure, you are no longer losing data, your performance is no longer shared between query and command databases, you have less I/O contention and bottlenecks. Moreover, you can now start to project data to different technologies to fit your specific needs.
By implementing event sourcing, you now have commands separated from queries and that’s where we can start to bring in our command query responsibility segregation.
CQRS
Split applications based on whether they create data or query data
So having created an event source database, separate from our state database, now we can start to think about how do we split our actual applications and not just our database, depending on whether or not they create the data (in our event source database) or if they query the data in our state database.
At this point, we’re pushing the data back and forth between those databases, and creating state records from our event sources using data projection. But we still haven’t done anything at the application layer. We’re still pushing all of your operations, whether they are commands or queries through a single application. So, there are opportunities to get even more positive outcomes.
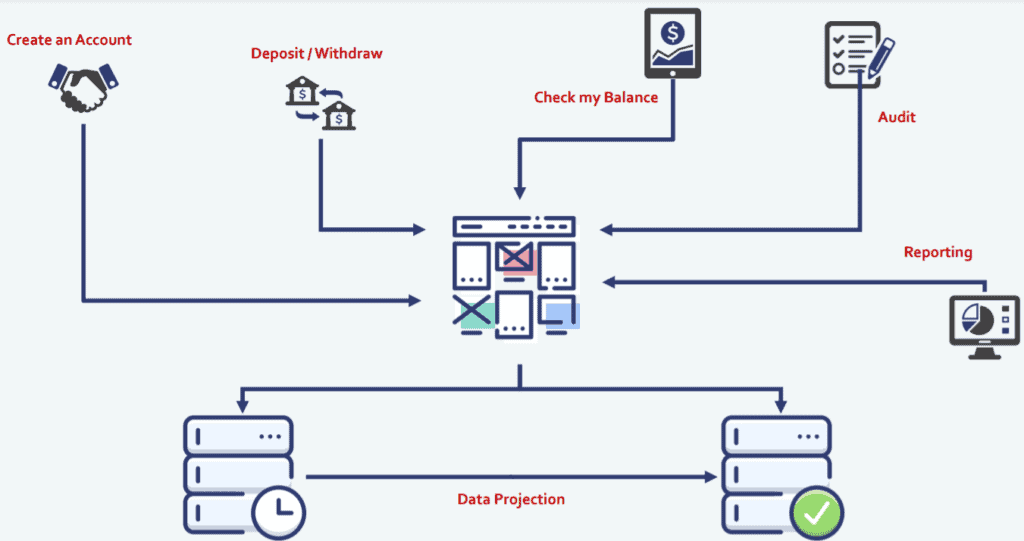
In most systems reads tend to outweigh writes because the read users, a.k.a Query users tend to do a lot more continuous work then the Command users. So, that gives us an opportunity to split those apart.
What we don’t want is to have an issue, where we want to change the functionality for our query users, we have to release a whole new application for our Command users or vice versa.So that we can get access to scalability, performance improvements, smaller releases, smaller blast radiuses.
Another good reason to split any application is for developers. From a developer perspective, it’s really nice to be able to work on small applications, where changes don’t impact huge amounts of code and where release and build pipelines are really small and fast. This allows teams to be really agile, deploy quickly, and run multiple instances without impacting other engineers.
As a result, your system will start looking more like this:
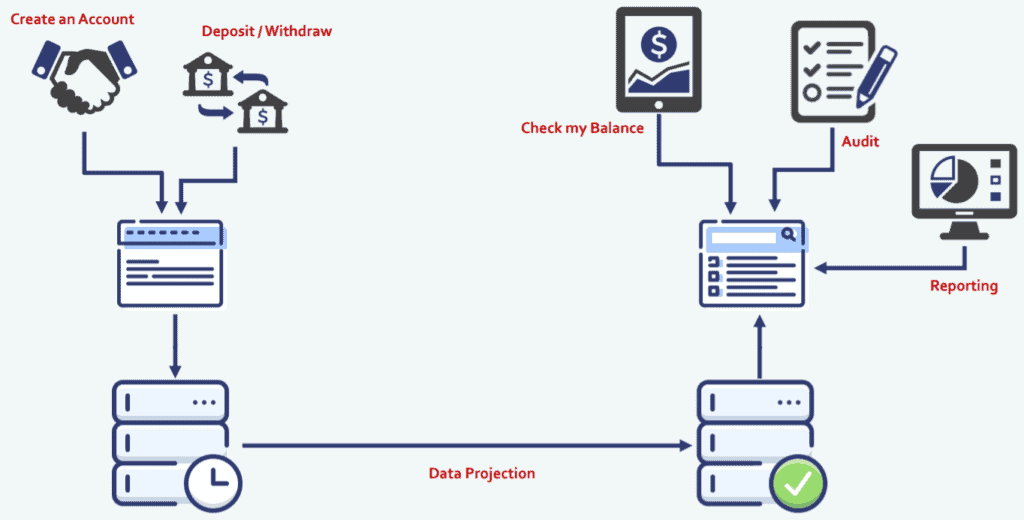
It’s the same as the previous diagram, but we’ve split apart that central application.
On the left hand side, we’ve created a command application from our business operations (Command), and that application is the one which speaks to our event source database. On the right hand side, we’ve created a separate application for our Query users. So, if you want to check your balance, get audit data, or a report, you can use the query application and it communicates with the State database. To underline again, there is a data projector between the event source database and the State database to produce the state in a format that is needed for Query applications.
Things to consider when splitting applications
One of the challenges that this system introduces is eventual consistency. There is a difference in time between the command happening, and the state being available and that’s something you would need to cater for in your projectors. With well written projectors and a smart business logic, you can easily manage the eventual consistency.
You also need to be aware of things like concurrent writes, or people writing to the database at the same time, versioning of records or events etc.
How We Do It
To give an example of what this looks like from my team’s point of view or how we do it:
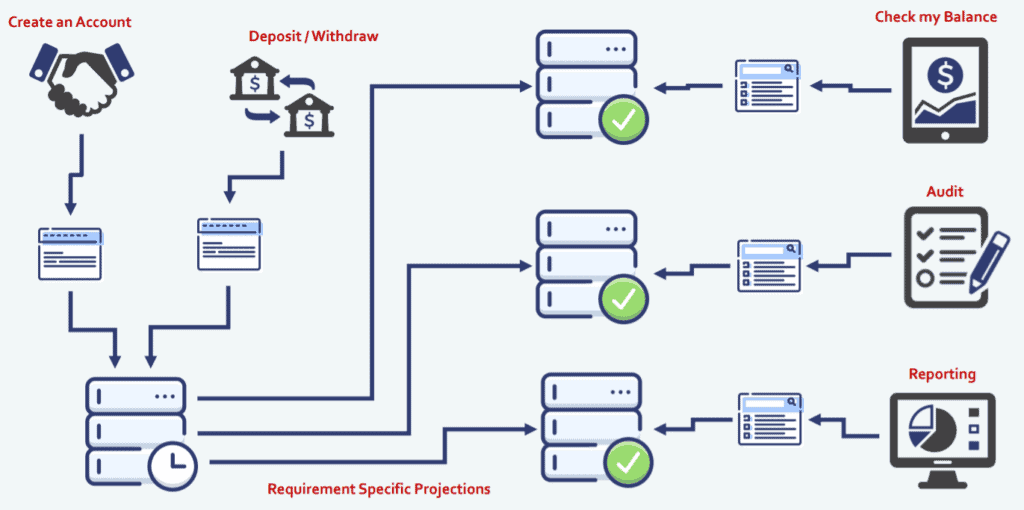
We have an event source database and we get all of the business operations funneling in through the business users and they use Command applications. Then requirements specific projectors shape the data, shape the state, and push them into specific databases for specific user groups. So if someone wants to check their balance, they query a different database than the audit users or reporting users. In each database, data is stored in a shape that really works for that user group.
Adding the CQRS layer, we actually break apart our applications, so for each group of users there is a specific application that really meets their needs. We have a command API that talks to the event source database, specifically for people who want to create an account. On the right, we have a query API that sits between our audit database and our audit users. So, when we want to make a change to the audit functionality of the application, we can release that application only, and not impact any of the other users.
And finally to give you an idea of the technologies we use at Fenergo:
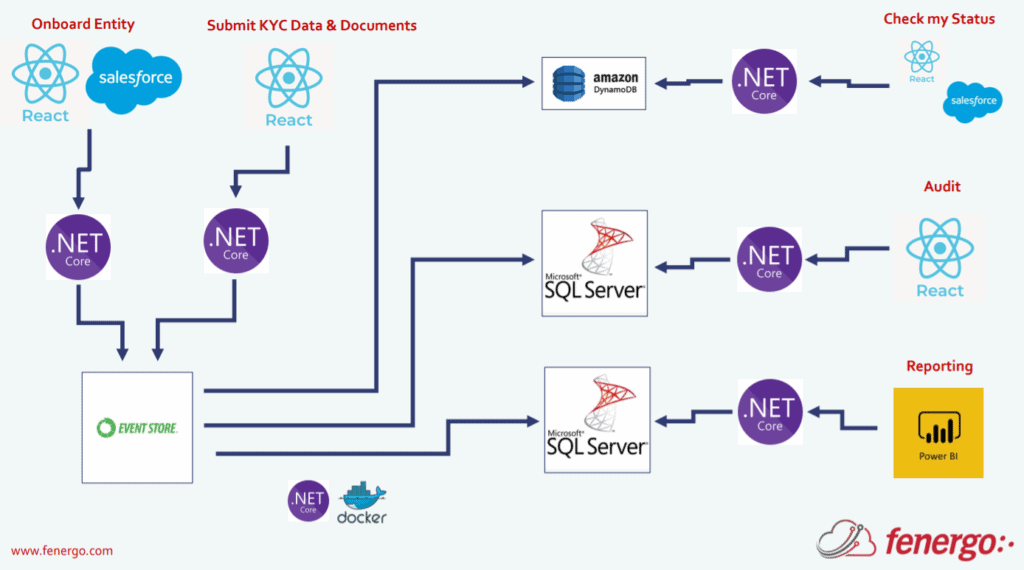
Those applications, the Command and Query API that we implement with CQRS are written in .NET Core, for our frontend application we use React and we do a lot of work with Salesforce to actually integrate with those APIs. For event sourcing we’re using a company called Event Store, as the source of our events. For our state databases we use DynamoDB, SQL Server. All of our projectors are containerised .NET Core applications.
Concluding Remarks
If your business is in a highly regulated industry, where you need to get access to this level of auditability, traceability and lack of data loss, event sourcing with CQRS might be a solution that works for you.