
The title might be a bit confusing, so let us explain what we will be talking about. If you are a software developer and you are looking for a real life analogy of what we are creating every day and WHY we develop software in the manner that we currently do, here is what we have gathered on the subject.
Imagine you are a CTO with 30 years of experience and suddenly you wake up in a new world where everyone is talking about microservices, Amazon Web Services, Azure, Kubernetes, OpenShift and you don’t understand what all the fuss is about.
“Can we continue using established patterns that didn’t let us down for the last 30 years? We know that they work perfectly fine. We have seen many fleeting technologies and software development patterns that didn’t get established in the end… but, let’s just let them explore.”
— CTO
In many cases the answer to that question would be “It depends” but today’s answer is “No, we can’t”. And why? Because of the increasing Complexity of software development.
Why do we develop software in the way we do?

Probably many of you remember an old children’s television series called “Once Upon a Time… Life”. Don’t underestimate the quality of this production. I know medical university professors who sometimes use this to teach their students in college.
We might not know why our body is behaving in the way it behaves but behind it lies the complexity of chemistry and biology of the human body. Once Upon a Time…
It is the same story with how we create our software. I believe it is not random; it is just intuitive and intuition is well trained artificial intelligence that knows the patterns but does not need to know the direct cause.
Why now, and not 30 years ago?
Let’s answer the CTO’s question. Once you know a tool well, you get to use it in more situations than it was designed for. However, the opposite is also true – software engineering is full of old, known for many years, and mostly unused patterns. They lie dormant until their time comes (ex. Document databases, Saga pattern). Monolithic approach was more than enough for handling the size of software projects 30 years ago, but since then our software evolved from being a CLI tool to something that can truly be called the web as a system of interconnectivity that even opens valves redirecting water to your home without human interaction.

It is the same with organisms’ evolution. First, we had single cellular organisms. Some of them were so advanced and “monolithic” that they made up the whole organism. They had everything: factories (mitochondrion), parsers that allowed transformation from DNA to proteins (ribosomes), communication with the outside environment, even multiple databases (cell nuclei). Those organisms were called multinucleate cells.
Long story short; the size and capabilities of organisms to influence its environment were just good enough to handle their challenges at the time. Same with our software. Complexity of our software increases proportionally to the amount of environment it “conquered” and is just good enough to deal with current challenges. If something is unnecessarily complex for current challenges, it is left for the future and will be used once the size of our software reaches the point we will need it to reduce complexity.
Saga Design Pattern
Let’s take a look at the Sage pattern which resembles the way complex organisms a.k.a. systems operate today.
But first things first, what is the saga software pattern?
A saga pattern is a sequence of local transactions where each transaction updates data within a single service. The first transaction in a saga is initiated by an external request corresponding to the system operation, and then each subsequent step is triggered by the completion of the previous one.
Same in our organisms. We have multiple organs (microservices) that are designed to asynchronously handle their tasks. Let’s imagine a common task that would be eating pizza with a lot of salt. Our organs will immediately start to break it down and process it in an asynchronous but choreographic way. You eat pizza, which is asynchronous, based on size, temperature and the presence of chillies :(, ect. Then your stomach needs to break it down, in the meantime the liver is preparing to process incoming food, the kidneys filter out the salt and so on.
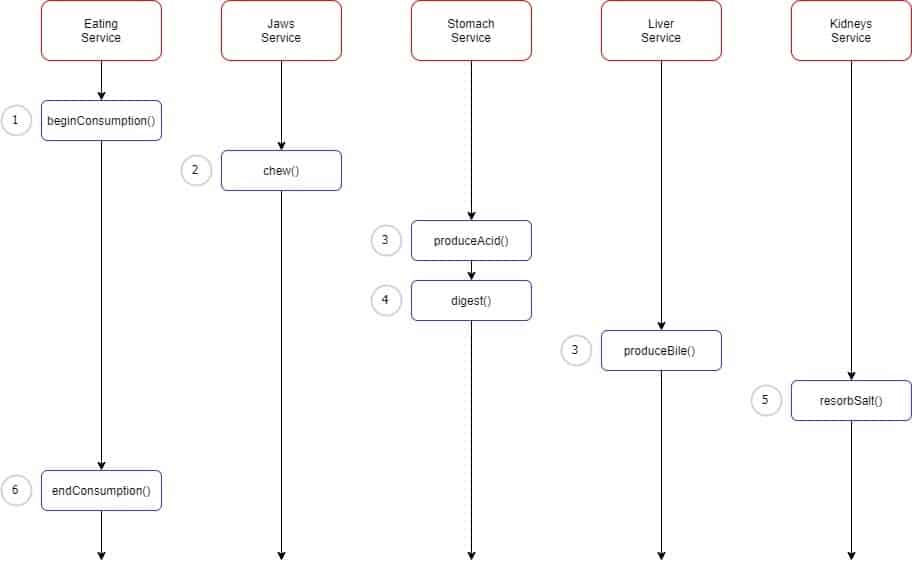
This behavior is the same as in the saga design of our modern applications:
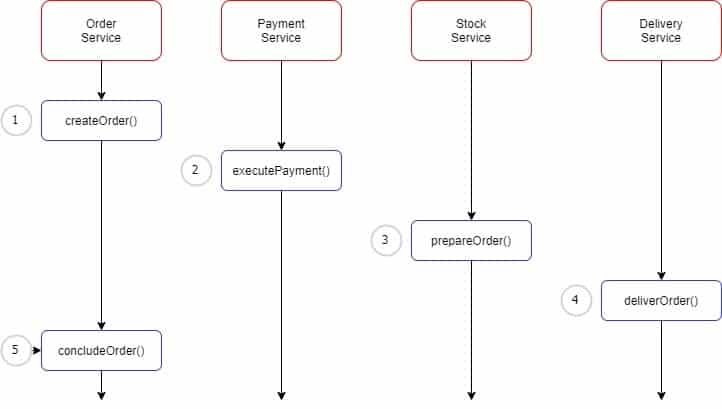
What are the benefits of using the Saga pattern?
It is true that engineers tend to push new patterns that they are trying out because their reward system promotes that behavior (and not without reason). However, patterns establish themselves out of the necessity to design and develop complex systems. If engineers tried to create the same application in monolithic architecture they could succeed, but mid to long-term maintainability would be much worse.
It’s like building a pyramid. You only need to understand how one building block behaves and then you just stack blocks until you end up with a pyramid. It allows us to see the system as a whole, understand it perfectly and build upon it easily.
Saga Pattern Example in AWS
We established it is beneficial to have separated and easy-to-understand microservices, rather than to build whole applications at once. But the size of a new big organism creates new challenges in front of us.
For example, it is easy in monolithic systems to guarantee that transactions are atomic.
But that’s not the case in microservices – being the complex organisms that they are. You need to coordinate different actions between the microservices, remembering that all of their functions are asynchronous (depending on fatigue and condition).
Then you need to transform messages between multiple microservices in an agreed and understandable manner. Just like in an organism, this is done with neurotransmitters.
A great example of this would be apache kafka and AWS Step functions. Step functions guarantee sequential order while maintaining asynchronous behavior.
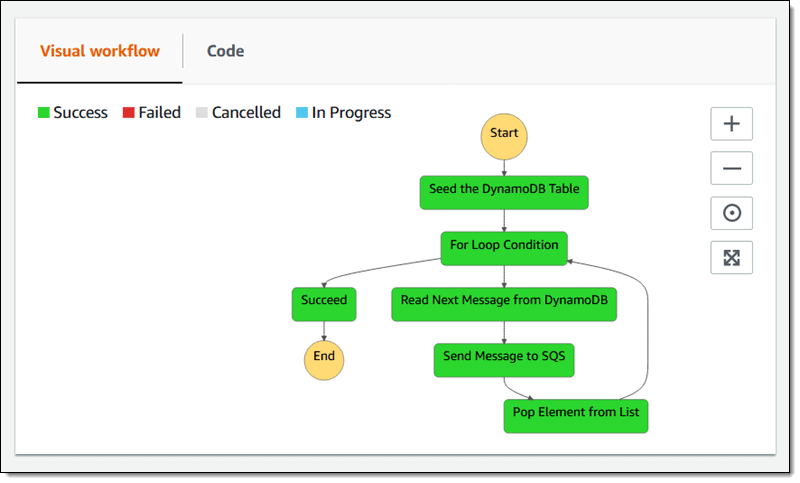
When a task fails, how do we handle that?
Architects in Amazon have created for us a convenient way to revert changes. On every error encountered on each step we can “catch” error, reverting changes on every step with according workflow. So we end up with the same behavior as atomic transactions in monolith but using microservices architecture.
With such an approach, it is easy to:
- Extend current functionalities, you just add another step to step functions
- Implement a true single responsibility pattern in your code. For example, you need to create different files based on the flow but upload function / lambda / step can be common for every case it just needs the name of the file and content, optionally path.
- Perform tests quickly. With code split so much you can cover code that usually would require a full end to end test with few unit tests for each function / module.
- Treat every function like a black box from outside.
Summary – The Saga Pattern
If you are a CTO worried about jumping into microservices architecture, you don’t need to worry. If engineers are proposing this new architecture to you, be open because more often than not, they are doing it out of necessity. Microservices architecture should allow you to easily introduce new features in future and improve maintainability.
If you are an engineer and have just been granted permission to proceed with the Saga software pattern in the microservices world, remember that in that architecture there should be a strict line between microservices. Don’t create a hybrid of different services because even if you succeed it will defeat the purpose of “easily extending current implementation in the future” and no one will be happy about that. 🙂
—
This article is written by Michał Oleszczuk, Senior Tech Lead at Zartis. If you have any questions on the topic or would like additional information, please feel free to reach out to us!