
.NET Libraries: Introduction
Did you ever create a .NET library or nuget package used by your organization? Did it meet your expectations? Was it as easy to use as you imagined at the beginning? What happened when requirements of organization were changed (f.e. Moving from XML to JSON)? How many dependencies does your standard library have, and how often do you update them?
In this article, we’ll try to show you the most common mistakes developers make creating their libraries and propose some solutions to avoid such mistakes in future software projects.
1. Library interface
The first thing you notice after installing a new dependency in your project is its interface. How you interact with types you brought into your project or application.
Did you ever regret installing a library, because its interface got overly complicated quickly? You can stop for a second here and think about it. Why was that?
Did the type or properties names make sense? Was the configuration of classes consistent or mixed (class based settings, builder pattern, Action<T> based configuration)? Did you have to manually install peer dependencies to make it work? Did it work the first time you compiled and ran your program?
How can you avoid that? My suggestion is to… Just use it by yourself. You can follow TDD principles. Or even better – give it to a coworker with no explanation. If they are comfortable using it without giving a description on how to make things work, you got it. A perfect indicator of a simple, clear, readable library interface.
2. Public Types
You should be very thoughtful about what you make public in your library. Nowadays almost every developer is using IntelliSense, or ReSharper as an aid in programming. Those tools can scan libraries and show you types and/or extension methods provided by them.
Imagine you created a library, which takes string as an parameter and you created your own string Trim extension method to help you manage input parameters. Do you really want everyone that installed your package to use that extension method? Did you consider a case when you made a bug in that method, but fixing the bug will break services that rely on current implementation?
How can you avoid this mistake? Use access modifiers to your advantage. Make public classes public and hide everything else using private, internal or protected access modifiers. Do not share too much, because it is always easier to make private classes public, then making public types private again.
3. Logging
Before installing any kind of logging framework into your library you should ask yourself a question: Why do I need logging in your package? Is it for me – developer – to help me diagnose potential problems? Or is it for potential users to help them understand the internal state? Or maybe you use logging to show potential user validation errors?
Why is it so important to answer those questions before adding such a simple dependency as logging into the package?
One of the biggest concerns are dependencies. Adding a logging library into your package will force users of this package to configure that logging framework before using it. When you design your library to be aware that logging may not be configured, or providing default implementation to log to standard output will improve users experience, but you are still adding dependency. How can you be sure that service using your package will use the same logging framework? How can you be sure that someone won’t install your library inside another library using a different logging framework? Developers then will have to configure multiple logging frameworks to use both libraries.
There are few ways to resolve that issue. None of those is better than the other. You as a designer should decide which method you will use:
- Ditch logging and using custom exceptions – this solution may seem to be out of the box, but it is very powerful. You are indicating that some operation went wrong and you are leaving the decision in package user’s hands.
- Implement your own abstractions for logging – providing a custom ILog interface is great, because you are not adding any dependencies. You can also provide your implementations for most common logging frameworks (see Extensibility).
- Use .NET Core logging approach – Microsoft created their own abstractions over logging in their package. Why not use it when someone already gave a thought about it and tested it? Services using your package can configure ILoggerFactory up to their needs.
- Use F# technics – F# provides great types (Result<T>) that can be used to return information about methods misuse. You don’t have to use F#, or implement those types by yourself. You can use language-ext, that implements Result<T> for you. Remember that pulling this library will add a dependency, so it may be better for you to implement that concept by yourself.
4. Exceptions
Are you adding custom exception types into your library? Are you catching exceptions in your library to log and rethrow them again? Are you removing stack traces from your exceptions? Did you use this pattern inside of your library?
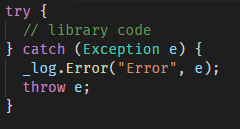
What is the problem with that, you may ask. You have to understand that the runtime for your library is provided by service using it. That means all exceptions (catched and uncatched) will be handled by your service. And how do you invoke library code in your service? Is your code exactly the same?
If you are going to catch an exception in your library to log it only, DO NOT DO IT. Especially do not use “throw e;” – it will remove stack trace and will cause problems during debugging.
Let your service catch library exceptions and log them.
You should be very thoughtful about any exceptions thrown by your library. Remember that System.Exception class contains a Message property that you can use for your advantage. If you spend some time creating meaningful messages for your exceptions, your users will be delighted. In my opinion you should create a message containing information why it was thrown and how to avoid this exception. You can read about best practices here. If you don’t like exceptions at all, you may consider using railroad oriented programming.
5. Dependencies
You should be very careful about packages you are installing in your library, especially when the package is going to be used across the whole company. Keep in mind that every dependency will require updates in the future. Why should I care, you may ask?
Updates to your dependencies bring important changes into dependencies. Beginning at small improvements in interface or performance, and ending at security patches. But are you prepared for that? Or you rather live in dependency hell?
When you are creating a library, it is better to avoid dependencies as much as possible. It is often possible to copy utility types, from dependencies you want to use, into your library and make them internal. Just think, next time: Is it worth installing EntityFramework into your library to fetch a single value from the database? Or should you use .NET built in IDbConnection?
If you decide you need dependencies, consider the pattern proposed at Extensibility.
6. Debuggability
When you are creating a library for your organization, you should enable other people to debug your code, even if you are the owner of the code. Your coworkers can fix simple problems for you, and all you will have to do is to approve a pull request.
Besides already mentioned meaningful messages in the Exceptions section, do not hide stack traces produced by your library. This is crucial information that helps so much during debugging.
Also, you should consider building your package with debugging symbols enabled. Those symbols can be published as a separate package to your packages feed. This way your production code does not contain any debugging information, but developers can pull those from packages feed and have better experience with debugging.
7. Extensibility
Abstract everything and allow the library users to decide about implementation. That should be a thought behind every good library implementation. There are multiple concerns in your library that you should abstract:
- Logging
- Serialization
- Communication planes
- Querying data
- Storing data
- IoC
- Etc.
Abstracting concerns mentioned above brings a lot of benefits for you and your library:
- You are reducing number of dependencies, mitigating dependency hell
- User of your package can decide which implementations to use
- When your organization decide that log4net, or Castle.Windsor is banned, all you have to do is to create small dll with implementation of concrete framework
- Granular approach is beneficial, when you want to implement rolling update of your dependencies
There are multiple examples of this approach:
8. Library Documentation
Library documentation is very tricky. Very often the time pressure forces us to abandon documentation alltogether. I would encourage you to ask yourself a question: Why does my library need documentation? Can I refactor the library interface to remove the need for documentation?
In my opinion, the most valuable documentation shows examples on how the library should be used. It also presents the view of the creator of the library – the thought behind. It is very important to present limitations of the library to avoid improper usage or nasty code hacks. The easiest thing you can do is to use codedoc. Use examples, exceptions, see also.
Keep in mind, that if you choose to document your code, you must be very careful. Documentation is not compiled or checked. If you change implementation, you must apply corrections to documentation too. Also, Don’t over document your code. Documentation should add quality touch to your package. It is our responsibility not to confuse others with excessive project files and provide an efficient experience for users.
Summary: .NET Libraries
Implementing libraries may seem to be a simple task, but implementing it properly requires some time in thinking about design. There are multiple concerns to consider, to not create one-time-use package. Here is a quick summary from each section:
- Library interface – keep it clear, simple, consistent and easy to use. Ask your coworkers to help you.
- Public types – carefully choose what types you share. It is always easier to make types public than private.
- Logging – try to avoid logging inside libraries. You don’t know which logging framework library users will choose. If you need logging – abstract it.
- Exceptions – use exceptions to communicate with the user. Make exception messages meaningful and avoid removing stacktraces, which will make debugging process hard.
- Dependencies – avoid the library dependencies as much as possible. If you need dependencies, try to abstract it.
- Debuggability – enable your library users to help you. Publish debug symbols with your package.
- Extensibility – allow your users to choose their own runtime. Let them decide what implementations should they use.
- Documentation – be responsible and do not over document your code. Try to explain the limitations of your library.
Thankfully, there are multiple good examples that we can benefit from. We wish you all great success with your future packages!
—
This blog is written by Sławomir Pawluk, Software Development Engineer at Zartis. Feel free to reach out to us at Zartis in case you have any questions or request further information on the topic.
More on the Zartis tech blog:
